U n compilateur transforme un programme écrit en langage
évolué en une suite d'instructions élémentaires exécutables par une
machine. La construction de compilateurs a longtemps été considérée
comme une des activités importantes en informatique, elle a suscité le
développement de nombreuses techniques et théories maintenant
classiques. La compilation d'un programme est réalisée en au moins
trois phases, la première (analyse lexicale) consiste à découper le
programme en petites entités: opérateurs, mots réservés, variables,
constantes numériques, alphabétiques, etc. La deuxième phase (analyse
syntaxique) consiste à expliciter la structure du programme sous forme
d'un arbre, appelé arbre de syntaxe abstraite, chaque noeud de cet
arbre correspond à un opérateur et ses fils aux opérandes sur lesquels
il agit. La troisième phase (génération de code) construit la suite
d'instructions du micro-processeur à partir de l'arbre de syntaxe
abstraite; elle peut donner lieu à des développements sophistiqués,
constituant toujours un domaine de recherche très actif.
Nous nous limiterons ici à une vision simple des deux premières
étapes. Elle permettent d'illustrer l'utilisation des notions
d'automates (analyse lexicale) et de grammaires (analyse syntaxique).
En outre, l'analyse syntaxique fait partie des nombreuses situations
où l'on transforme une entité, qui se présente sous une forme plate et
difficile à manipuler, en une forme structurée adaptée à un traitement
efficace. Le calcul symbolique ou formel, le traitement automatique du
langage naturel constituent d'autres exemples. Notre but n'est pas de
donner ici toutes les techniques permettant d'écrire un analyseur
syntaxique, mais de suggérer à l'aide d'exemples comment il faudrait
faire. L'ouvrage de base pour l'étude de la compilation est celui de
A. Aho, R. Sethi et J. Ullman [21]. On peut aussi se référer
aux premiers chapitres de [30] pour une présentation
plus théorique.
Les caractères constituent souvent dans un langage de programmation un
type primitif. C'est bien le cas en Java. Les constantes de type
caractère sont notées entre apostrophes 'a', 'b',
'c', etc. Les caractères spéciaux sont définis avec la barre
renversée '\n' (line-feed), '\r' (retour
charriot), '\t' (tabulation), '\\' (backslash),
'\'' (apostrophe), '\"' (guillemet). La différence entre
line-feed et retour-charriot est hélas subtile, car très
dépendante du système d'exploitation. Dans le système Unix, le passage
à la ligne suivante se fait avec le seul caractère line-feed. En
MacOS, c'est retour-charriot. En Windows, c'est la séquence
retour-charriot suivi de line-feed, une remarque à savoir pour
le seul caractère figurant sur chaque ligne! Souvent, les éditeurs de
texte lisent indifféremment les trois formats.
Selon les langages de programmation, la distinction entre caractères
et entiers est plus ou moins stricte. En Java, les caractères forment
un sous-ensemble des entiers. Ce sont des entiers courts
non-signés. Ils occupent complètement un mot de 16 bits, et ne peuvent
être convertis implicitement qu'à des entiers signés sur 32 bits de
type int.
La fonction associant à chaque caractère un entier est la fonction de
codage des caractères. Plusieurs codes ont successivement
existé; ces codes deviennent plus complexes avec
l'internationalisation des langages de programmation pour représenter
les caractères par exemple en indi, en chinois, en coréen, ou en
alphabet cyrillique, ainsi que les caractères accentués du français,
de l'espagnol et des langages d'Europe centrale. Le consortium Unicode et l'ISO (International Organization for
Standardization) ont défini un code universel, standard ISO 10646-1
utilisant 65534 valeurs.
Les 127 premières valeurs constituent le code ASCII (American
Standard Codes for Information Interchange) des caractères
américains (c'est-à-dire les caractères latins non-accentués) donné en
hexadecimal par la table 2.1. On remarque que les
codes des chiffres sont des valeurs consécutives, ainsi que pour les
lettres minuscules et majuscules. Les 20 premières valeurs, non
imprimables, peuvent être obtenues en appuyant simultanément sur la
touche CTRL (contrôle) du clavier et sur celle du caractère
correspondant quatre lignes plus bas dans le tableau. Ainsi nul,
soh, \t, \n s'obtiennent en effectuant
CTRL-@, CTRL-A, CTRL-I, CTRL-J.
| |
|
0 |
|
1 |
|
2 |
|
3 |
|
4 |
|
5 |
|
6 |
|
7 |
|
8 |
|
9 |
|
a |
|
b |
|
c |
|
d |
|
e |
|
f |
|
| 00 |
|
nul |
|
soh |
|
stx |
|
etx |
|
eot |
|
enq |
|
ack |
|
bel |
|
\\ |
|
\t |
|
\n |
|
vt |
|
np |
|
\r |
|
so |
|
si |
|
| 10 |
|
dle |
|
dc1 |
|
dc2 |
|
dc3 |
|
dc4 |
|
nak |
|
syn |
|
etb |
|
can |
|
em |
|
sub |
|
esc |
|
fs |
|
gs |
|
rs |
|
us |
|
| 20 |
|
|
|
! |
|
" |
|
# |
|
$ |
|
% |
|
& |
|
' |
|
( |
|
) |
|
* |
|
+ |
|
, |
|
- |
|
. |
|
/ |
|
| 30 |
|
0 |
|
1 |
|
2 |
|
3 |
|
4 |
|
5 |
|
6 |
|
7 |
|
8 |
|
9 |
|
: |
|
; |
|
< |
|
= |
|
> |
|
? |
|
| 40 |
|
@ |
|
A |
|
B |
|
C |
|
D |
|
E |
|
F |
|
G |
|
H |
|
I |
|
J |
|
K |
|
L |
|
M |
|
N |
|
O |
|
| 50 |
|
P |
|
Q |
|
R |
|
S |
|
T |
|
U |
|
V |
|
W |
|
X |
|
Y |
|
Z |
|
[ |
|
\ |
|
] |
|
|
|
_ |
|
| 60 |
|
` |
|
a |
|
b |
|
c |
|
d |
|
e |
|
f |
|
g |
|
h |
|
i |
|
j |
|
k |
|
l |
|
m |
|
n |
|
o |
|
| 70 |
|
p |
|
q |
|
r |
|
s |
|
t |
|
u |
|
v |
|
w |
|
x |
|
y |
|
z |
|
{ |
|
& |
|
} |
|
~ |
|
del |
|
Figure 2.1 : Le code ASCII en hexadécimal
Les 256 premières valeurs de l'Unicode constituent le code ISO 8859-1
(Latin-1) avec les lettres accentuées ou les caractères particuliers
latins.
En fait, l'Unicode a maintenant dépassé les 16 bits, sa nouvelle norme
(codage ISO 10646-2) demande 31 bits pour inclure encore plus de
langues. Malheureusement, beaucoup de programmes utilitaires des
vieux systèmes d'exploitation tels que le système Unix, conçu en 1970,
(ou son incarnation publique Linux), utilisent la représentation
ASCII; par exemple, les caractères des noms de fichiers ne peuvent
dépasser les 7 bits de l'ASCII. Pour rester compatible (compatibilité
ascendante), une représentation en longueur variable, l'UTF-8, a été
définie, comme indiqué sur la table 2.2. En UTF-8,
les codes ASCII sont inchangés et tiennent toujours sur un octet; les
codes ISO-Latin tiennent sur deux octets (le premier commençant par
les 3 bits 110; le deuxième par les 2 bits 10; la valeur significative
tenant facilement sur les 11 bits restants); les autres codes tiennent
sur trois octets (le premier commençant par 1110; les deux autres par
10; la valeur significative tenant aussi facilement sur les 16 bits
restants). Le nombre des premiers bits valant 1 donnent le nombre
d'octets utilisés pour le cas non-ASCII; la garde 10 en tête de chacun
des autres octets permet la synchronisation en cas de perte d'octets.
| |
Unicode |
|
|
Code UTF-8 |
| |
|
|
|
|
|
|
|
|
| |
0000 -- 007f |
|
|
0xxxxxxx |
|
|
|
|
| |
0080 -- 07ff |
|
|
110xxxxx |
|
10xxxxxx |
|
|
| |
0800 -- ffff |
|
|
1110xxxx |
|
10xxxxxx |
|
10xxxxxx |
Figure 2.2 : Le code de longueur variable UTF-8 en binaire
En Java, quelques fonctions permettent de caractériser les caractères
sans avoir à considérer leur code. Par exemple isLetter, isDigit, isLetterOrDigit donnent un résultat booléen signifiant
que leur argument est une lettre, un chiffre ou l'un des deux. On
pourrait les définir ainsi (dans le cas ASCII);
static boolean isDigit (char c) {
return '0' <= c && c <= '9';
}
static boolean isLetter (char c) {
return 'a' <= c && c <= 'z' && 'A' <= c && c <= 'Z';
}
static boolean isLetterOrDigit (char c) {
return isLetter(c) || isDigit(c);
} |
La fonction inverse du codage prend une valeur entière et essaie de la
traduire en caractère. Il faut faire attention à ne pas confondre les
deux valeurs. Ainsi le caractère correspondant au chiffre x sera
donné par la formule '0' + x, c'est à dire les valeurs
hexadécimales c0 pour 0, c1 pour 1, c2 pour
2, etc.
| 2.2 |
Chaînes de caractères |
|
Les chaînes de caractères sont en première approximation des tableaux
de caractères. Mais, souvent leur représentation est plus compacte. En
Java, les chaînes de caractères sont représentés par des objets de la
classe String. La longueur de la chaîne s est donnée par x.length(). Attention, c'est un appel à la méthode length (avec
des parenthèses) et non un champ de donnée comme dans le cas des
tableaux. Quelques autres méthodes utiles permettent d'écrire s.equals(t) pour tester l'égalité de s et t, ou s.indexOf(c) pour donner la première occurence de c dans s, ou
s.charAt(i) pour rendre le caractère à la position i dans s.
L'opérateur + produit la concaténation de deux chaînes. Ainsi s+t
est la chaîne constituée de s puis de t. Si l'une des deux
opérandes n'est pas une chaîne, l'autre est transformée en chaîne de
caractère en lui appliquant la méthode toString (de sa classe).
Enfin, les chaînes de caractères sont immuables, c'est-à-dire
des constantes non modifiables. Ceci simplifie le partage des chaînes
de caractères, par exemple, entre plusieurs processus concurrents
(cf. le chapitre sur la concurrence).
L'expression Integer.parseInt(s) associe à la chaîne de
caractères s l'entier qu'elle dénote en décimal. Symétriquement,
x+"" produit la chaîne de caractères correspondant à la
représentation décimale de x. La fonction parseInt peut être
définie par:
static int parseInt (String s) throws NumberFormatException {
int r = 0;
for (int i = 0; i < s.length(); ++i) {
if (!Character.isDigit (s.charAt(i)))
throw new NumberFormatException();
r = 10 * r + s.charAt(i) - '0';
}
return r;
} |
La fonction parseInt ne fait que calculer, pour la
chaîne s constituée des caractères s0, s1, ...sp, le
polynôme Si=0p si 10p-i par la méthode de
Horner. Réciproquement, la fonction symétrique, appelons-la integerToString, s'écrit:
static String integerToString (int x) {
String s = "";
while (x != 0) {
s = s + ('0' + x % 10);
x = x / 10;
}
return s;
} |
Cette dernière fonction existe aussi en standard en Java. On
l'obtient en calculant l'expression new Integer(x).toString() ou
plus simplement x+"" comme déjà mentionné.
Exercice 7
Ecrire un programme pour la méthode toString de la classe Integer.
Exercice 8
Ecrire une fonction integerToString avec deux arguments x et
b retournant la chaîne de caractères représentant l'entier x dans
la base b.
Toutefois, la fonction integerToString n'est pas très efficace,
puisqu'à chaque itération une nouvelle chaîne de caractères s est
construite avec seulement un caractère de plus. Au total, elle prend
un espace-mémoire en O(l 2) si on pose l = log10 x. Il
est impossible de faire autrement avec les variables de la classe String dont les valeurs sont imuables. Fort heureusement, la classe
StringBuffer permet de manipuler des chaînes de caractères
modifiables en réservant un espace mémoire paramétrable à leur
création. Le programme précédent qui s'écrit comme suit prend
maintenant un espace-mémoire en O(l):
static String integerToString (int x) {
StringBuffer s = new StringBuffer();
while (x != 0) {
s = s.append ('0' + x % 10);
x = x / 10;
}
return new String(s);
} |
| 2.3 |
Alphabets, mots, langages |
|
D'un point de vue théorique, une chaîne de caractères est appelé un
mot; les caractères sont des lettres; l'ensemble des
lettres constitue un alphabet. Autrement dit, si A est un
alphabet, un mot construit sur A est une suite finie f = a1 a2
... an de lettres prises dans A (n ³ 0); l'entier n est
la longueur de f. On note par e le mot vide, c'est
le mot de longueur 0. Le produit de deux mots f et g est
obtenu en écrivant f puis g à la suite, on le note fg. Donc la
longueur de fg est égale à la somme des longueurs de f et de g.
Un mot f est un facteur de g s'il existe deux mots g' et
g'' tels que g = g' f g''; f est facteur gauche de g si
g = fg''; c'est un facteur droit si g = g'f. L'ensemble des
mots sur l'alphabet A est noté A*. On remarque qu'on a
trivialement e f = f e = f et que (fg)h = f(gh)
(lois d'un monoïde).
Exemple 1 Mots sans carré.
Soit l'alphabet A = { a, b, c }. On construit la suite de mots
suivante f0 = a, et, pour n ³ 0, on obtient fn+1 à partir
de fn en remplaçant a par abc, b par ac et c par
b. Ainsi:
f0 = a f1 = abc f2 = abcacb
f3 = abcacbabcbac
Il est assez facile de voir que fn est un facteur gauche de
fn+1 pour n ³ 0, et que la longueur de fn est 3 ×
2n-1 pour n ³ 1. On peut aussi montrer que, pour tout n,
aucun facteur de fn n'est un carré, c'est à dire que,
si gg est un facteur de fn, alors g = e. Remarquons à
ce propos que, si A est un alphabet composé des deux lettres a et
b, les seuls mots sans carré sont a,b,ab,ba,aba,bab. La
construction ci-dessus, montre l'existence de mots sans carré de
longueur arbitrairement grande sur un alphabet de trois lettres.
Exemple 2 Expressions préfixées.
Les expressions arithmétiques en notation (polonaise) préfixe peuvent
être considérées comme des mots sur l'alphabet A = { +,
*, a }, on remplace tous les nombres par la lettre a pour
en simplifier l'écriture. En voici deux exemples,
f = * a a
g = * + a * a a + * a a * a a
Exemple 3 Un mini-langage de programmation.
Considérons l'alphabet A suivant, où les ``lettres `` sont des mots sur
un autre alphabet:
A = { begin, end, if, then, else,
while, do, ;, p, q, x,
y, z }
Alors
f = while p do begin if q then x else y ; zend
est un mot de longueur 13, qui peut se décomposer en
f = while p dobegin g ; zend
g = if q then x elsey
Un langage est un ensemble de mots. Par exemple, si A= {a,
b}, le langage L = {an bn | n ³ 0} des mots contenant
n fois la lettre a suivis d'autant de fois de b. On peut aussi
considérer le langage des L' des mots contenant autant de fois a
que de fois b. Bien sûr, on a L Ì L'. Si A' = { (,
) }, on peut considérer le langage D des mots sur A' bien
parenthésés, c'est-à-dire avec exactement une parenthèse fermante pour
chaque parenthèse ouvrante. Par exemple, ()(()()) Î D. Si
on remplace la parenthèse ouvrante par la lettre a et la parenthèse
fermante par la lettre b, on obtient un langage L'' bien
parenthésé sur A, et on a L Ì L'' Ì L' Ì A*.
Le produit de mots peut être étendu au produit de langages. Si L et
L' sont deux langages sur l'alphabet A, le produit LL' désignera
l'ensemble des mots obtenus par produit d'un mot de L et de L'.
LL' = { fg | fÎ L, g Î L'}
On notera aussi Ln pour le produit LL... L itéré n fois. Par
convention L0 = { e }. Enfin l'opération étoile qui
désigne les mots formés par produits de mots de L est définie par:
L* = L0 È L È L2 ... È Ln ...
Remarquons que cette notation est bien cohérente avec l'écriture
utilisée, A*, pour désigner tous les mots sur l'alphabet A.
| 2.4 |
Expressions régulières |
|
Les expressions régulières permettent de dénoter simplement un
ensemble de mots. Par exemple pour désigner tous les mots du langage
{an b | n ³ 0 }, on écrit a*b, c'est-à-dire les mots
contenant un nombre quelconque (éventuellement nul) de a suivi d'un
b. De même b*a représente l'ensemble des mots commençant par un
nombre quelconque de b suivi d'un seul a. Pour représenter l'union
de ces deux ensembles, on écrit a*b + b*a.
Définition 1
Soit A un alphabet. Une expression régulière
est toute
expression formée à partir du mot vide e, des lettres de A
avec les opérations produit, somme et étoile. Le langage [[ e
]] dénoté par l'expression régulière e est défini
récursivement par:
| [[ e ]] = { e } |
|
[[ a ]] = { a } |
|
[[ (e) ]] = [[ e ]] |
| [[ e e' ]] = [[ e ]] [[ e' ]] |
|
[[ e* ]] = [[ e ]]* |
|
[[ e + e' ]] = [[ e ]] È [[ e' ]] |
Parfois l'opération somme e+e' est aussi écrite avec une barre
verticale, donnant e | e'. La première notation est plus utilisée
en informatique théorique, la deuxième dans les manuels de description
des langages de programmation. Nous utilisererons indistinctement les
deux notations. Une autre notation fréquente est e+ pour désigner
e* sans la chaîne vide e. Ainsi e* = e + e+.
Exemple 4 Mots contenant un facteur donné.
Soit A = {a, b} et u Î A*. L'ensemble des mots ayant u en
facteur s'écrit (a+b)*u(a+b)*. Par exemple, si u = aab, on obtient
(a+b)*aab(a+b)*.
Exemple 5 Mots contenant un nombre pair de lettres.
Sur l'alphabet A = {a, b}. L'expression régulière (b* a b* a)*
désigne les mots contenant un nombre pair de a. On peut aussi utiliser
(b + a b* a)* pour ce même ensemble. Maintenant, si on exige un nombre
pair de a et de b, on arrive à l'expression pas si évidente
((a+ba(aa)* b)(b(aa)* b)*(a+ba(aa)* b) + b(aa)* b)*.
Exemple 6 Noms de fichiers.
Dans les systèmes de fichiers, on opère souvent sur tous les fichiers
dont le nom comporte un suffixe donné, par exemple.html. On les
désigne par une expression régulière de la forme *.html. Le
symbole ? est aussi parfois utilisé. Formellement ? est
un joker dénotant l'alphabet de toutes les lettres de code
ASCII, et * est une abbréviation pour (?)*. Ainsi
a*.java désigne tous les fichiers dont le nom commence par un a
et de suffixe .java; de même, .???* dénote tous les
fichiers dont le nom a au moins 3 lettres commençant par un point.
Exemple 7 Identificateurs et nombres.
Soit A = {a, b, ... z } et C = {0, 1, 2, ... 9
}. Ecrivons [a-z] pour dénoter A et [0-9] pour C. Un nom de
variable ou de fonction (un identificateur) est représenté par
l'expression régulière [a-z]([a-z]+[0-9])*. Une constante entière
est dénotée par [0-9]+. Donc un identificateur est une suite de
chiffres ou de lettres commençant toujours par une lettre; un nombre
est une suite non vide de chiffres.
Exemple 8 Motifs de filtrage.
Dans les systèmes informatiques, les expressions régulières sont
aussi utilisées pour retrouver des motifs dans des fichiers, par
exemple pour imprimer les lignes contenant le motif (comme le fait la
commande grep du système Unix -- get regular
expression). On utilise des caractères fictifs
^ et $ pour dénoter le début et la fin de ligne. Alors
les lignes vides sont obtenues par le motif
"^$"; les lignes blanches par
"^_*$"; une suite non
vide de caractères blancs est "__*";
etc. Ici le sens de * n'est pas le même que pour les noms de fichiers;
a* a le sens normal a* des expressions régulières.
Les expressions régulières ont fait l'objet d'études intensives, leur
structure est bien plus riche qu'on ne pourrait le penser a
priori. Elles n'ont pas vraiment de représentations canoniques. Mais,
si on rajoute 0 pour Ø et si on pose 1 = e et e
£ e' pour e + e' = e', on obtient un certains nombres de lois
définissant ce qu'on appelle une algèbre de Kleene:
| (1) |
e + f = f + e |
|
| (2) |
e + (f + g) = (e + f) + g |
|
| (3) |
e + 0 = e |
|
| (4) |
e + e = e |
|
| (5) |
e(fg) = (e f) g |
|
| (6) |
1 e = e 1 = e |
|
| (7) |
e (f + g) = e f + e g |
|
| (8) |
(e + f) g = e g + f g |
|
| (9) |
0 e = e 0 = 0 |
|
| (10) |
1 + e e * = e * |
|
| (11) |
1 + e * e = e * |
|
| (12) |
f + e g £ g Þ e*f £ g |
|
(12') |
e g £ g Þ e*g £ g |
| (13) |
f + g e £ g Þ fe* £ g |
|
(13') |
g e £ g Þ ge* £ g |
En fait, toutes les égalités entre expressions régulières peuvent être
obtenues à partir de ces 13 équations (Les équations 12-12' et 13-13'
sont équivalentes). Par exemple, pour montrer que a* a* = a *, on
note que 1 + a a* = a* par (10). D'où a a* £ a* par
définition de £. Donc a* a* £ a* par (12').
Réciproquement, a* a* = (1 + a a*) a* par (10). D'où a* a* =
a* + a a* a* par (8) et (6). Donc a* £ a* a*.
Exercice 9
Montrer qu'on a dans les algèbres de Kleene: e £ e' £ e
Û e = e'.
Exercice 10
Montrer en utilisant les lois des algèbres de Kleene que (a*)* = a *,
(a *b)* a * = (a + b)*, a (ba)* = (ab)* a, et
a * = (aa)* + a (aa)*.
Exercice 11
Montrer les équations précédentes par des raisonnements directs sans
utiliser les algèbres de Kleene.
Exercice 12
Montrer que e = f + ge implique que e = g*f.
On veut donc extraire un flot de lexèmes dans la très longue chaîne de
caractères constituant le texte d'un programme. On élimine tous les
caractères inutiles ou redondants. Par exemple, les caractères blancs
(espace, tabulation, retour-charriot, line-feed) sont souvent
inutiles; un seul suffit plutôt qu'une bonne dizaine consécutifs. De
la même manière, les commentaires sont inutiles (pour compiler un
programme). Un lexème est une entité importante pour la compilation
telle qu'un identificateur, une constante numérique, un opérateur, une
chaîne de caractères, une contante caractère, etc.
Comme vu dans l'exemple 7, un identificateur ou
une constante entière peuvent être définis par des expressions
régulières. Il en va de même pour tous les autres lexèmes. Un nombre
flottant est une suite de chiffres suivis éventuellement d'un point
(.) et d'une suite de chiffres. Pour la notation de
l'ingénieur, c'est un peu plus compliqué puisqu'il faut expliquer les
formats de la partie significative et de la partie exposant. Une
chaîne de caractères commence et finit par un guillemet ("); à
l'intérieur c'est une suite quelconque de caractères différent de
guillemet. Toutefois après une barre renversée (\) on peut
aussi mettre un guillemet à l'intérieur de la chaîne.
Les définitions de lexèmes sous forme d'expressions régulières sont
données par:
| lettre |
= |
a|b|... z|A|B|... Z|_ |
| chiffre |
= |
0|1|2|3|4|5|6|7|8|9 |
| identificateur |
= |
lettre (lettre | chiffre)* |
| nombre |
= |
chiffre+ |
| nombre_flottant |
= |
nombre (e | . nombre) |
| chaine |
= |
" ((~")+ \")* " |
en adoptant la notation ~c pour désigner les
caractères différents de c. Avec de telles définitions, nous pouvons
enfin penser à écrire un programme pour rechercher des lexèmes dans
une très longue chaîne de caractères. Nous définissons d'abord la
représentation des lexèmes dans notre langage de programmation
favori. Dans une deuxième phase, on produira le programme
correspondant à la description par expressions régulières.
Les lexèmes sont représentés par des objets de la classe Lexeme
suivante avec trois champs de données: le champ nature indique
si le lexème est un nombre, un identificateur, un opérateur ou un
délimiteur comme parenthèse ou crochet ou la fin de fichier; le champ
valeur stocke la valeur d'un entier dans le cas où le lexème est
un nombre; le champ nom est la chaîne de caractères représentant
le nom d'un identificateur dans le cas où le lexème est un
identificateur. Ces trois champs ne sont pas utiles simultanément,
mais, pour simplifier, nous considérons ces trois champs pour chaque
lexème.
class Lexeme {
final static int L_Nombre = 0, L_Id = 1, L_Plus = '+', L_Moins = '-',
L_Mul = '*', L_Div = '/', L_ParG = '(', L_ParD = ')',
L_CroG = '[', L_CroD = ']', L_EOF = -1;
int nature;
int valeur;
String nom;
Lexeme (int i) { nature = L_Nombre; valeur = i; }
Lexeme (String s) { nature = L_Id; nom = s; }
Lexeme (char op) { nature = op; }
} |
La fonction Lexeme.suivant retourne le prochain lexème dans le
flot d'entrée de l'analyseur lexical. Elle saute les caractères blancs
(espace, tabulation, line-feed, retour-chariot) et retourne,
selon le premier caractère non-blanc rencontré, un lexème
identificateur, nombre entier ou symbole opérateur-délimiteur. La
définition des fonctions ident ou nombre suit exactement
la valeur de l'expression régulière définissant les lexèmes
identificateur ou nombre. La fonction avancer passe au caractère
suivant dans le flot d'entrée et le stocke dans la variable globale
c.
static char c; // caractère courant
static Lexeme suivant() {
sauterLesBlancs();
if (Character.isLetter(c)) return new Lexeme (ident());
else if (Character.isDigit(c)) return new Lexeme (nombre());
else switch (c) {
case '+': case '-': case '*': case '/':
case '(': case ')': avancer(); return new Lexeme (c);
default: throw new Error ("Caractère illégal");
}
}
static void avancer() { c = in.readChar(); }
static void sauterLesBlancs() {
while ( Character.isWhitespace (c) )
avancer();
}
static String ident() {
StringBuffer r;
while (Character.isLetterOrDigit (c)) {
r = r.append (c);
avancer();
}
return new String(r);
}
static int nombre() {
int r = 0;
while (Character.isDigit (c)) {
r = r * 10 + c - '0';
avancer();
}
return r;
} |
Exercice 13
Compléter le programme pour chercher des lexèmes pour les nombres
flottants et les chaînes de caractères de telle manière que sur le
texte suivant
class PremierProg {
public static void main (String[ ] args){
System.out.println ("Bonjour tout le monde!");
System.out.println ("fib(20) = " + fib(20));
}
} |
les résultats successifs produits par appel à la fonction
Lexeme.suivant seront:
L_Id(class) L_Id(PremierProg) L_AccG L_Id(public) L_Id(static)
L_Id(void) L_Id(main) L_ParG L_Id(String) L_CroG L_CroD L_Id(args)
L_ParD L_AccG L_Id(System) L_Point L_Id(out) L_Point L_Id(println)
L_ParG L_Chaine(Bonjour tout le monde!) L_ParD L_PointVirgule
L_Id(System) L_Point L_Id(out) L_Point L_Id(println) L_ParG
L_Chaine(fib(20) = ) L_Plus L_Id(fib) L_ParG L_Nombre(20) L_ParD
L_ParD L_PointVirgule L_AccD L_AccD L_EOF |
Exercice 14
Modifier l'analyseur lexical pour sauter les commentaires comme en
Java. (Il va y avoir un problème pour la fin de ligne).
Exercice 15
En se servant d'une pile, simuler une calculette HP, utilisant la notation
polonaise suffixe, pour évaluer des expressions arithmétiques.
Notre présentation simplifiée de l'analyse lexicale ne doit pas faire
oublier qu'il existe des outils très sophistiqués (comme lex de
M. Lesk) permettant d'obtenir automatiquement de très bons analyseurs
lexicaux à partir d'une description de haut niveau avec des
expressions régulières. Cela simplifie grandement l'écriture de
compilateurs, car souvent l'analyse lexicale est délicate à
réaliser. En outre, ces outils sont très efficaces pour générer
rapidement des automates finis de taille quasi minimale. (La notion
d'expression régulière est reliée à la notion d'automate fini que nous
verrons plus tard).
| 2.6 |
Arbres de syntaxe abstraite |
|
Un compilateur produit un arbre de syntaxe abstraite à partir du texte
du programme. En effet, un compilateur teste si le programme est
syntaxiquement correct (grâce à la phase d'analyse syntaxique que nous
verrons plus loin), mais il en produit aussi une représentation
structurée sous forme arborescente, un arbre de syntaxe
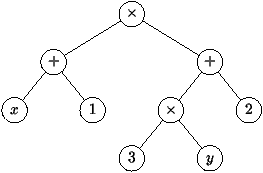
abstraite. Prenons le simple exemple des expressions arithmétiques
construites à partir des nombres et de noms de variables avec les
opérateurs +, -, × et /. Un arbre de syntaxe abstraite
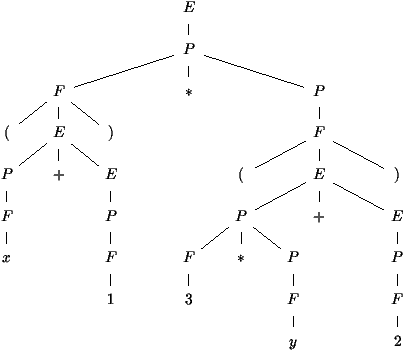
pour l'expression (x+1)× (3 × y+2) est représenté sur la
figure 2.3.
Figure 2.3 : Arbre de syntaxe abstraite
La représentation de ces arbres de syntaxe abstraite, ou ASA, ou
termes va se faire grâce à une classe Terme qui définit ce qu'on
appelle un type disjonctif dans d'autres langages de programmation
(ML): l'ensemble des termes est l'union d'arbres binaires dont les
noeuds sont des opérateurs pris parmi +, -, × et /, et
les feuilles sont des variables ou des constantes entières. Ce qui
nous donne:
class Terme {
final static int ADD = 0, SUB = 1, MUL = 2, DIV = 3, MINUS = 4,
VAR = 5, CON = 6;
int nature;
int valeur;
String nom;
Terme a1, a2;
Terme (int t, Terme a) {nature = t; a1 = a; }
Terme (int t, Terme a, Terme b) {nature = t; a1 = a; a2 = b; }
Terme (String s) {nature = VAR; nom = s; }
Terme (int v) {nature = CON; valeur = v; }
} |
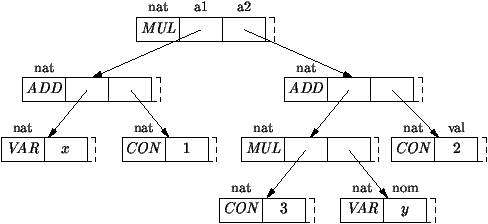
Comme pour la représentation précédente des lexèmes, les champs de
données utilisés correspondent à tous les cas possibles. Le champ nature indique si le noeud correspond à une addition, soustraction,
multiplication, un moins unaire, ou s'il s'agit d'une feuille pour les
variables et les constantes; le champ nom donne l'identificateur
pour les feuilles qui sont des variables; le champ valeur donne
la constante entière pour les feuilles qui sont des constantes. Dans
le cas de l'exemple de la figure 2.3, l'arbre de
syntaxe abstraite est implanté comme indiqué sur la figure
2.4. On peut le construire par les instructions
suivantes:
Figure 2.4 : Représentation d'un arbre de syntaxe abstraite
Terme t = new Terme (MUL,
new Terme (ADD, new Terme ("x"), new Terme (1)),
new Terme (ADD,
new Terme (MUL, new Terme (3), new Terme ("y")),
new Terme (2))); |
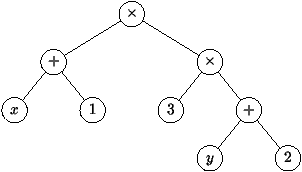
Les arbres de syntaxe abstraite (ASA) constituent une des structures les
plus abstraites associées à un programme. Dans l'exemple précédent,
les textes de programme (x+1)× (3 × y+2), ou (x+1)×
((3 × y) +2) ou ((x+1)× (3 × y +(2))) correspondent
au même ASA. Les détails de la ``syntaxe concrète ``, avec leurs
excès de parenthèses, ont été oubliés. Mais cette expression est, bien
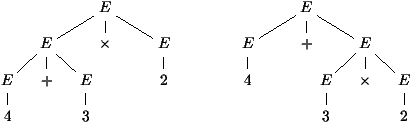
sûr, différente de l'expression de la figure 2.5
dont l'ASA est différent. Il correspond à l'expression (x+1)× (3
× (y + 2)).
Figure 2.5 : Un autre arbre de syntaxe abstraite
Pour construire des ensembles de mots, on utilise la notion de grammaire. Une grammaire G comporte deux alphabets A et
VN, un axiome S qui est une lettre appartenant à VN
et un ensemble R de règles.
- L'alphabet A est dit alphabet terminal, tous les mots
construits par la grammaire sont constitués de lettres de A.
- L'alphabet VN est dit alphabet auxiliaire ou non-terminal, ses lettres servent de variables intermédiaires
servant à engendrer des mots. Une lettre S de VN, appelée
axiome, joue un rôle particulier.
- Les règles sont toutes de la forme S ® u où S est une
lettre de VN et u un mot comportant des lettres dans A È VN.
Exemple 9
A = { a, b }, VN = { S, T, U },
l'axiome est S.
Les règles sont données par :
| S ® aT bS |
|
T ® aT bT |
|
U ® bU aU |
| S ® bU aS |
|
T ® e |
|
U ® e |
| S ® e |
|
|
|
Pour engendrer des mots à l'aide d'une grammaire, on applique le
procédé suivant:
On part de l'axiome S et on choisit une règle de la forme S ®
u. Si u ne contient aucune lettre auxiliaire, on a terminé. Sinon,
on écrit u = u1Tu2. On choisit une règle de la forme T ®
v. On remplace u par u' = u1vu2. On répète l'opération sur u'
et ainsi de suite jusqu'à obtenir un mot qui ne contient que des
lettres de A.
Dans la mesure où il y a plusieurs choix possibles à chaque
étape, on voit que le nombre de mots engendrés par une grammaire est
souvent infini. Mais certaines grammaires peuvent n'engendrer aucun
mot. C'est le cas par exemple des grammaires dans lesquelles tous les
membres droits des règles contiennent un lettre de VN.
On peut formaliser le procédé qui engendre les mots
d'une grammaire de façon un peu plus précise en définissant la notion
de dérivation. Etant donnés deux mots u et v contenant des
lettres de A È VN, on dit que u dérive directement de v
pour la grammaire G, et on note v ® u, s'il existe deux
mots w1 et w2 et une règle de grammaire S ® w de G
tels que v = w1S w2 et u = w1ww2. On dit aussi que v se
dérive directement en u. On dit que u dérive de v, ou que
v se dérive en u, si u s'obtient à partir de v par une suite
finie de dérivations directes. On note alors: v ®* u, ce qui
signifie l'existence de w0, w1, ... wn (n ³ 0) tels
que w0 = v, wn = u et, pour tout i (0 £ i < n), on a
wi® wi+1.
Un mot est engendré par une grammaire G, s'il dérive de
l'axiome et ne contient que des lettres de A, l'ensemble de tous les
mots engendrés par la grammaire G, est le langage
engendré par G; il est noté L( G).
Reprenons la grammaire G de
l'exemple 9 et effectuons
quelques dérivations en partant de S. Choisissons S ® aTbS,
puis appliquons la règle T ® e. On obtient:
S ® aTbS ® abS
On choisit alors d'appliquer S ® b UaS . Puis, en
poursuivant, on construit la suite
S ® aTbS ® abS ® abbUaS ® abbbUaUaS ® abbbaUaS
® abbbaaS ® abbbaa
D'autres exemples de mots L ( G) sont bbaa
et abbaba obtenus à l'aide de calculs similaires:
S ® bU aS ® bbU aU aS ® bbaU aS
® bbaaS ® bbaa
S ® aT bS ® abS ® abbUaS
® abbaS ® abbabU aS ® abbabaS
® abbaba
Plus généralement, on peut montrer que, pour cet exemple, L
( G) est constitué de tous les mots qui contiennent autant de
lettres a que de lettres b.
| 2.8 |
Exemples de Grammaires |
|
| 2.8.1 |
Les systèmes de parenthèses |
|
Le langage des systèmes de parenthèses joue un rôle important tant du
point de vue de la théorie des langages que de la programmation. Dans
les langages à structure de blocs, les begin end ou les
| \prog| se comportent comme des parenthèses ouvrantes et
fermantes. Dans des langages comme Lisp, le décompte correct des
parenthèses fait partie de l'habileté du programmeur. Dans ce qui
suit, pour simplifier l'écriture, on note a une parenthèse ouvrante
et b une parenthèse fermante. Un mot de {a, b}* est un système
de parenthèses s'il contient autant de a que de b et si tous ses
facteurs gauches contiennent un nombre de a supérieur ou égal au
nombre de b. Une autre définition possible est récursive, un système
de parenthèses f est ou bien le mot vide (f = e) ou bien
formé par deux systèmes de parenthèses f1 et f2 encadrés par
a et b (f = af1bf2).
Cette nouvelle définition se traduit sous la forme de la grammaire
suivante:
A = { a, b }, VN = { S }, l'axiome est S, les règles sont
données par:
S ® aS bS S ® e
On notera la simplicité de cette grammaire, la définition
récursive rappelle celle des arbres binaires, un tel arbre est
construit à partir de deux autres comme un système de parenthèses
f l'est à partir de f1 et f2.
La grammaire précédente a la particularité, qui est parfois un
inconvénient, de contenir une règle dont le membre droit est le mot
vide. On peut alors utiliser une autre grammaire déduite de la
première qui engendre l'ensemble des systèmes de parenthèses non
réduits au mot vide, dont les règles sont:
|
|
| S ® aSbS |
|
S ® aSb |
|
S ® abS |
|
S ® ab |
|
| 2.8.2 |
Les expressions arithmétiques préfixées |
|
Ce sont grosso modo les expressions que l'on trouve dans le langage
Lisp. Dans une expression arithmétique préfixée, les opérateurs
figurent avant leurs opérandes. Le nombre de leurs opérandes est
délimité par un système de parenthèses. Pour simplifier, les opérandes
atomiques (constantes entières ou variables) sont représentées par la
lettre a. Leur définition récursive se traduit immédiatement par la
grammaire suivante:
A = { +, × , ( , ) , a }, VN = { S }, l'axiome est S, les
règles sont données par:
S ® ( + S S )
S ® ( × S S)
S ® a
Deux exemples d'expressions arithmétiques
préfixées sont engendrés comme suit:
| S |
|
® |
|
|
| |
|
| S |
|
® |
|
( T S S ) |
| |
|
|
|
( T ( T S S
) ( T S S ) ) |
| |
|
|
|
( T ( T S ( T S S ) ) ( T
( T S S ) ( T S S ) ) ) |
| |
|
|
|
( × ( + a ( × a a) )
( + ( × a a) ( × a a) ) ) |
| S ® (T1 S ) |
|
S ® (T2 S S ) |
|
S ® a |
|
|
|
|
|
|
| T1 ® Ö |
|
T1 ® - |
|
T2 ® + |
|
T2 ® × |
|
T2 ® - |
|
T2 ® / |
| 2.8.3 |
Les expressions arithmétiques |
|
Il s'agit maintenant de donner une grammaire pour les expressions
arithmétiques infixes, c'est-à-dire notées comme en mathématiques.
Pour simplifier, on ne considère que les deux opérateurs × et +.
Les parenthèses permettent de regrouper les opérations, elles ne sont
pas nécessaires pour délimiter un produit dans une somme, puisque que
× est plus prioritaire que +. Dans un premier temps, nous
supposons que les opérandes atomiques sont représentées par le symbole
a. Les expressions arithmétiques sont donc engendrées par la
grammaire suivante:
A = { +, × , ( , ) , a } , VN = { E, P, F},
l'axiome est E, les règles sont données par:
| E ® P |
|
P ® F |
|
F ® a |
| E ® P + E |
|
P ® F × P |
|
F ® ( E ) |
( a + a ) × ( a × a + a )
Il représente l'expression
(x+1)× (3 × y +2)
dans laquelle les opérandes atomiques sont remplacées par le symbole
a.
On peut se convaincre que cette expression est engendrée par la
grammaire en commençant la dérivation qui l'engendre à partir de l'axiome:
| E |
|
® |
|
P ® F × P ® ( E ) × P ® ( P+E ) × P |
| |
|
® |
|
( F+E ) × P ® ( a+E ) × P ® ( a+P) × P |
| |
|
® |
|
( a+F) × P ® ( a+a) × P ® ( a+a) × F |
| |
|
® |
|
( a+a) × ( E ) ® ··· ®
( a + a ) × ( a × a + a ) |
Les lettres de l'alphabet auxiliaire ont été choisies pour
rappeler la signification sémantique des mots qu'elles
engendrent. Ainsi E, P et F représentent respectivement les
expressions, produits et facteurs. Dans cette terminologie, on constate
que toute expression est somme de termes et que tout produit est produit
de facteurs. Chaque facteur est ou bien réduit à la variable a ou
bien formé d'une expression entourée de parenthèses. Ceci traduit
les dérivations suivantes de la grammaire.
| E ® P + E ® P + P + E ...
|
|
P+P+P ... +P |
| P ® F × P
® F × F × P ... |
|
F× F× F ... × F |
La convention usuelle de priorité de l'opération × sur
l'opération + explique que l'on commence par engendrer des sommes
de termes avant de décomposer les termes en produits de facteurs, en
règle générale pour des opérateurs de priorités quelconques on
commence par engendrer les symboles d'opérations ayant la plus faible
priorité pour terminer par ceux correspondant aux plus fortes.
On peut généraliser la grammaire pour faire intervenir
beaucoup plus d'opérateurs. Il suffit d'introduire de nouvelles
règles comme par exemple
E ® E - P P ® P / F
si l'on souhaite introduire des soustractions et des divisions. Comme
ces deux opérateurs ont la même priorité que l'addition et la
multiplication respectivement, il n'a pas été nécessaire
d'introduire de nouveaux éléments dans VN. Il faudrait faire
intervenir de nouvelles variables auxiliaires si l'on introduit de
nouvelles priorités.
Nous avons abusivement considéré le symbole a comme représentant
unique des facteurs les plus simples. En fait, les expressions
arithmétiques sont aussi formées avec des constantes numériques et des
noms de variables. En fait, l'alphabet terminal est l'ensemble des
lexèmes définis par un analyseur lexical. Dans notre cas, une syntaxe
plus réaliste sera définie comme suit:
A = { +, × , ( , ) , id, nombre } ,
VN = { E, P, F},
l'axiome est E, les règles sont données par:
| E ® P |
|
P ® F |
|
F ® id |
| E ® P + E |
|
P ® F × P |
|
F ® nombre |
| |
|
|
|
F ® ( E ) |
Plusieurs abréviations existent pour raccourcir la longueur d'une
grammaire. Par exemple, on peut factoriser les parties gauche en
utilisant la barre verticale ( | ) pour séparer les parties droites
possibles. Ainsi la grammaire précédente s'écrirait:
| E ® P | P + E |
|
P ® F | F × P |
| F ® id | nombre | ( E ) |
|
| E := P | P + E |
|
P := F | F × P |
| F := id | nombre | ( E ) |
|
Mais la forme la plus usuelle de notation abrégée est la BNF, sous
laquelle on représente les grammaires des langages de programmation La
BNF (Backus Naur Form) tient son nom de John Backus, le
concepteur de FORTRAN, et de Peter Naur qui l'ont utilisé pour
donner une définition formelle du langage Algol 60.
Dans la convention d'écriture adoptée pour la BNF, les éléments
de VN sont des suites de lettres et symboles comme MultiplicativeExpression, UnaryExpression. Les règles ayant le
même élément dans leur partie gauche sont regroupées et cet élément
n'est pas répété pour chacune d'entre elles. Le symbole ® est
remplacé par : suivi d'un passage à la ligne. Quelques
conventions particulières permettent de raccourcir l'écriture:
one of permet d'écrire plusieurs règles sur la même ligne;
les éléments de l'alphabet terminal A sont les mots-clé,
comme class, if, then, else, for,
..., et les opérateurs ou séparateurs comme
+ * / - ; , ( ) [ ] = == < >.
Dans les grammaires données en annexe, on compte dans la grammaire de
Java 131 lettres pour l'alphabet auxiliaire et 251 règles. Il est hors
de question de traiter ici ce trop long exemple. Nous nous limitons
aux exemples donnés plus haut dans lesquels figurent déjà toutes les
difficultés que l'on peut trouver par ailleurs.
Notons toutefois que l'on trouve la grammaire des expressions
arithmétiques sous forme BNF dans l'exemple de la grammaire de Java
donnée en annexe. On trouve en effet à l'intérieur de cette
grammaire:
AdditiveExpression:
MultiplicativeExpression
AdditiveExpression + MultiplicativeExpression
AdditiveExpression - MultiplicativeExpression
MultiplicativeExpression:
UnaryExpression
MultiplicativeExpression * UnaryExpression
MultiplicativeExpression / UnaryExpression
MultiplicativeExpression % UnaryExpression
UnaryExpression:
PreIncrementExpression
PreDecrementExpression
+ UnaryExpression
- UnaryExpression
UnaryExpressionNotPlusMinus
UnaryExpressionNotPlusMinus:
PostfixExpression
~ UnaryExpression
! UnaryExpression
CastExpression
PostfixExpression:
Primary
Name
PostIncrementExpression
PostDecrementExpression
Primary:
PrimaryNoNewArray
ArrayCreationExpression
PrimaryNoNewArray:
Literal
this
( Expression )
ClassInstanceCreationExpression
FieldAccess
MethodInvocation
ArrayAccess |
Le but de l'analyse syntaxique est de déterminer si un mot appartient
ou non au langage engendré par une grammaire. Il s'agit donc, étant
donné un mot f de construire la suite des dérivations qui a permis
de l'engendrer. Si l'on pratique ceci à la main pour de petits
exemples, on peut utiliser la technique classique dite ``essais-erreurs`` consistant à tenter de deviner à partir d'un mot la
suite des dérivations qui ont permis de l'engendrer. Cette suite se
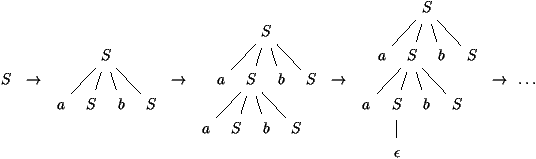
présente plus clairement sous forme d'un arbre, dit arbre de
dérivation ou arbre syntaxique, dont des exemples sont donnés
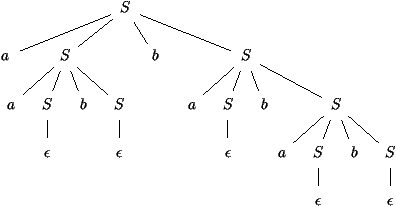
figures 2.6 et 2.7. Il s'agit de ceux obtenus
pour les mots aabbabab et (x+1)× (3× y+2) engendrés
respectivement par la grammaire des systèmes de parenthèses et par
celle des expressions arithmétiques.
L'arbre de dérivation de la figure 2.6 est construit
progressivement comme suit:
L'étiquette S de la racine de l'arbre est l'axiome de la
grammaire. Chaque noeud interne est étiqueté par une variable X
non-terminale (appartenant à VN); en outre, le mot u obtenu en
lisant de gauche à droite les étiquettes de ses fils est tel que X
® u est une règle de la grammaire. Enfin, le mot f dont on fait
l'analyse est constitué des étiquettes des feuilles lues de gauche à
droite.
Figure 2.6 : Arbre de dérivation de aabbabab
Figure 2.7 : Arbre de dérivation d'une expression arithmétique
Plusieurs dérivations peuvent correspondre à un même arbre
syntaxique. Mais, en général, il n'existe qu'un seul arbre de
dérivation pour un mot donné du langage engendré. L'existence de
plusieurs arbres de dérivations pour un même mot signifie souvent
qu'il existe plusieurs interprétations possibles pour celui-ci. On
dit qu'alors la grammaire est ambiguë. Toutes les grammaires données
plus haut sont non-ambiguës. En revanche, la grammaire suivante pour
les expressions arithmétiques est ambiguë.
A = { +, × , ( , ) , id, nombre } ,
VN = { E },
l'axiome est E, les règles sont données par:
| E ® E + E |
|
E ® id |
|
E ® ( E ) |
| E ® E × E |
|
E ® nombre |
|
Figure 2.8 : Grammaire ambiguë
L'arbre de dérivation est parfois appelé arbre de syntaxe concrète
pour le distinguer de l'arbre de syntaxe abstraite. L'arbre de
syntaxe abstraite est bien plus compact que le précédent. Il s'obtient
par des transformations simples à partir de l'arbre de dérivation. C'est
bien ce que fait un analyseur syntaxique.
| 2.10 |
Analyse descendante récursive |
|
Deux principales techniques sont utilisées pour effectuer l'analyse
syntaxique. Etant donnés une grammaire G et un mot f, il
s'agit de construire la suite des dérivations de G conduisant
de l'axiome au mot f,
S ® u1 ® u2 ... un-1 ® un = f
La première technique consiste à démarrer de l'axiome S et
à tenter de retrouver u1, puis u2 jusqu'à obtenir un = f,
c'est l'analyse descendante. La seconde, l'analyse
ascendante procède en sens inverse, il s'agit de commencer par
deviner un-1 à partir de f puis de remonter à un-2 et
successivement jusqu'à l'axiome S. Nous décrivons ici sur des
exemples les techniques d'analyse descendante, l'analyse ascendante
sera traitée dans un paragraphe suivant.
La première méthode que nous considérons s'applique à des grammaires
très particulières, mais que l'on rencontre très souvent. Dans ces
cas, l'algorithme d'analyse syntaxique devient une traduction fidèle
de l'écriture de la grammaire. On utilise pour cela autant de
fonctions qu'il y a d'éléments dans VN, chacune d'entre elles est
destinée à reconnaître un mot dérivant de l'élément correspondant de
VN. Prenons le cas des expressions arithmétiques de la
section 2.8.3, l'analyseur récursif descendant
s'écrit:
static Lexeme lc; // lexème courant
static void avancer() {lc = Lexeme.suivant(); }
static Terme expression() {
Terme t = produit(); switch (lc.nature) {
case Lexeme.L_Plus: avancer(); return new Terme (ADD, t, expression());
case Lexeme.L_Moins: avancer(); return new Terme (MINUS, t, expression());
default: return t;
}
}
static Terme produit() {
Terme t = facteur(); switch (lc.nature) {
case Lexeme.L_Mul: avancer(); return new Terme (MUL, t, produit());
case Lexeme.L_Div: avancer(); return new Terme (DIV, t, produit());
default: return t;
}
}
static Terme facteur() {
Terme t; switch (lc.nature) {
case Lexeme.L_ParG: avancer(); t = expression();
if (lc.nature != Lexeme.L_ParD) throw new Error ("Il manque ')'");
break;
case Lexeme.L_Nombre: t = new Terme (lc.val); break;
case Lexeme.L_Id: t = new Terme (lc.nom); break;
default: throw new Error ("Erreur de syntaxe");
}
avancer();
return t;
} |
Ce programme réutilise les constantes et les fonctions définies pour
l'analyseur lexical présenté plus haut. Les fonctions expression, produit et facteur correspondent aux
variables auxiliaires E, P et F. Le corps de chaque fonction
consiste à considérer les différentes parties droites possibles pour
les règles de grammaires associées à ces variables. Ainsi, pour E,
on choisit entre les trois cas P+E, P-E et P selon le lexème
courant rencontré après avoir lu un produit. Si c'est l'opérateur +
ou -, on est dans le cas où la partie droite est P+E, ou P-E. On
fait de même pour choisir entre F × P, F /P
et F dans le cas d'un produit en décidant sur les lexèmes ×
ou /. Pour un facteur, la décision entre (E),
id ou nombre se fait en considérant le lexème
courant qui alors ne peut être que (, L_Id ou
L_Nombre.
Cette technique fonctionne bien ici car les membres droits des règles
de grammaire ont une forme particulière. Pour chaque élément X de
VN, l'ensemble des membres droits {u1, u2... up} de
règles, dont le membre gauche est X, satisfait les conditions
suivantes: les premières lettres des ui qui sont dans A, sont
toutes distinctes et les ui qui commencent par une lettre de VN
sont factorisables à gauche. Beaucoup de grammaires de langages de
programmation satisfont ces conditions: Pascal, Java.
Remarquons que notre grammaire des expressions arithmétiques ne
contient pas de récursivité à gauche, c'est-à-dire que VN ne
contient aucun X pouvant se dériver vers un mot Xu. Mais, si nous
avions plutôt pris les règles de grammaire suivantes:
| E ® P |
|
P ® F |
|
F ® id |
| E ® E + P |
|
P ® P × F |
|
F ® nombre |
| |
|
|
|
F ® ( E ) |
La valeur retournée par notre analyseur syntaxique est un arbre de
syntaxe abstraite. C'est bien ce que l'on cherche à construire. Comme
annoncé, l'analyseur syntaxique vérifie la conformité syntaxique de
l'expression sur le flot d'entrée et construit l'objet de la classe
Terme correspondant, dans le cas où l'entrée est un texte de
programme syntaxiquement correct.
La grammaire ne peut donc être récursive à gauche; on reprend donc la
grammaire de la section 2.8.3. Cette grammaire
aboutit à la construction d'arbres de syntaxe abstraite qui
privilégient l'association à droite pour les opérateurs de même
précédence. Ainsi P+P+P est interprété comme P+(P+P); de même F
× F × F correspond à F × (F × F).
Malheureusement, ce choix n'est pas le bon pour les opérateurs - ou
/, puisque P-P-P correspond d'habitude à (P-P)-P et non à
P-(P-P) comme généré par notre grammaire. Pour y remédier, tout en
respectant l'absence de récursivité à gauche, on change l'analyseur
pour générer les arbres de syntaxe abstraites avec un accumuleur. On
modifie donc les fonctions expression et produit comme
suit:
static Terme expression() {
Terme t = produit();
while (lc.nature == Lexeme.L_Plus) || (lc.nature == Lexeme.L_Moins) {
avancer();
switch (lc.nature) {
case Lexeme.L_Plus: t = new Terme (ADD, t, produit()); break;
case Lexeme.L_Moins: t = new Terme (MINUS, t, produit()); break;
}
return t;
}
}
static Terme produit() {
Terme t = facteur();
while (lc.nature == Lexeme.L_Mul) || (lc.nature == Lexeme.L_Div) {
avancer();
switch (lc.nature) {
case Lexeme.L_Mul: t = new Terme (MUL, t, facteur()); break;
case Lexeme.L_Div: t = new Terme (DIV, t, facteur()); break;
}
return t;
}
} |
Notre analyseur syntaxique récursif descendant s'arrête dès qu'il a lu
une expression arithmétique. Pourtant il se peut que le résultat ne
correspond pas à tout le flot d'entrée. Par exemple
3_2 sera considéré comme correct et reconnu comme la constante 3;
de même ( x+1) ( 3× y+2 ) est reconnu comme
l'expression x+1. Il faut donc vérifier si, après la lecture de
l'expression, le lexème courant arithmétique est bien la fin de
fichier L_EOF. La grammaire correspondante est alors:
A = { +, × , ( , ) , id, nombre, eof},
VN = { S, E, P, F},
l'axiome est S, les règles sont données par:
| E ® P |
|
P ® F |
|
F ® id |
| E ® P + E |
|
P ® F × P |
|
F ® nombre |
| S ® E eof |
|
|
|
F ® ( E ) |
| 2.11 |
Autres méthodes d'analyse syntaxique |
|
| 2.11.1 |
Méthode récursive descendante avec retours en arrière |
|
Une technique plus générale d'analyse syntaxique consiste à procéder
comme suit. On construit itérativement des mots u dont on espère
qu'ils vont se dériver en f. Au départ on a u = S (l'axiome de la
grammaire). A chaque étape de l'itération, on cherche la première
lettre de u qui n'est pas égale à son homologue dans f. On a ainsi
u = gyv f = gxh x¹ y
Si y Î A (alphabet terminal), on ne peut dériver f de
u, et il faut faire repartir l'analyse du mot qui a donné u. Sinon
y Î VN et on recherche toutes les règles dont y est le membre
gauche.
y ® u1 y ® u2 ··· y ® uk
On applique à u successivement chacune de ces règles, on obtient
ainsi des mots v1, v2, ... vk. On poursuit l'analyse, chacun
des mots v1, v2, ... vk jouant le rôle de u. L'analyse est
terminée lorsque u = f. La technique est celle de l'exploration
arborescente qui sera développée au chapitre 4.
On peut la représenter par la fonction suivante donnée sous une forme
informelle.
static boolean analyse (String u, String f) {
if (f.equals(u))
return true;
else {
Mettre f et u sous la forme f= gxh, u=gyv où x ¹ y
if ( y ÏA )
Pour toute règle y ® w faire
if (analyse (g + w + v, f))
return true;
return false;
}
} |
Remarquons que cette fonction ne marche toujours pas lorsque la
grammaire est récursive à gauche, comme dans la grammaire des
expressions arithmétiques de la page ??.
En outre, cette technique d'analyse engendre une détection d'erreur
imprécise, car les erreurs de syntaxe ne sont trouvées qu'après avoir
fait tous les choix de règle. Elle est aussi coûteuse en temps car on
effectue tous les essais successifs des règles et on peut parfois se
rendre compte, après avoir pratiquement terminé l'analyse, que la
première règle appliquée n'était pas la bonne. Il faut alors tout
recommencer avec une autre règle et éventuellement répéter plusieurs
fois ce mécanisme. La complexité de l'algorithme est ainsi une
fonction exponentielle de la longueur du mot f à analyser.
Si on suppose qu'aucune règle ne contient un membre droit égal au mot
vide, on peut diminuer la quantité de calculs effectués en débutant la
procédure d'analyse par un test vérifiant si la longueur de u est
supérieure à celle de f. Dans ce cas, la procédure d'analyse doit
avoir pour résultat false. Dans ces conditions, la fonction analyse donne un résultat même dans le cas de grammaires récursives à
gauche.
Une technique pour éviter les retours en arrière de l'analyse
descendante récursive consiste à deviner la règle à appliquer en
examinant les premières lettres du mot f à analyser. Plus
généralement, lorsque l'analyse a déjà donné le mot u et que l'on
cherche à obtenir f, on écrit comme ci-dessus
u = gSv f = gh
et les premières lettres de h doivent permettre de
retrouver la règle qu'il faut appliquer à S. Cette technique n'est
pas systématiquement possible pour toutes les grammaires, mais c'est
le cas sur un grand nombre de grammaires utiles, comme par exemple
celle des expressions préfixées ou une grammaire modifiée (par
factorisation à gauche) des expressions infixes. On dit alors que la
grammaire est LL.
Exemple 10 Expressions préfixées. Nous considérons la grammaire de
ces expressions:
A = { +, *, (, ), a }, VN = { S }, l'axiome est S, les
règles sont données par:
S ® ( + S S )
S ® ( * S S)
S ® a
Pour un mot f de A*, il est immédiat de déterminer u1 tel que
En effet, si f est de longueur 1, ou bien f= a et le
résultat de l'analyse syntaxique se limite à S ® a, ou bien
f n'appartient pas au langage engendré par la grammaire.
Si f est de longueur supérieure à 1, il suffit de connaître les
deux premières lettres de f pour pouvoir retrouver u1. Si ces
deux premières lettres sont ( +, c'est la règle S ® (+S
S) qui a été appliquée. Si ces deux lettres sont ( * alors
c'est la règle S ® (* S S ). Tout autre début de règle
conduit à un message d'erreur.
Ce qui vient d'être dit pour retrouver u1 en utilisant les deux
premières lettres de f se généralise sans difficulté à la
détermination du (i+1)ème mot ui+1 de
la dérivation à partir de ui. On décompose d'abord ui et f
en:
ui = gi S vi f = gi fi
et on procède en fonction des deux premières lettres de fi.
-
Si fi commence par a, alors ui+1 = giavi
- Si fi commence par (+, alors ui+1 = gi(+SS) vi
- Si fi commence par (*, alors ui+1 = gi(*SS) vi
- Un autre début pour fi signifie que f n'est pas une expression
préfixée correcte, il y a une erreur de syntaxe.
On en déduit une fonction de construction d'un arbre de syntaxe
abstraite pour les expressions préfixées en reprenant les définitions
antérieures des classes pour les lexèmes et les termes:
static Terme expressionPrefixe() {
Terme t; switch (lc.nature) {
case Lexeme.L_Id: t = new Terme (lc.nom); break;
case Lexeme.L_ParG: avancer();
switch (lc.nature) {
case Lexeme.L_Plus: avancer(); t = expressionPrefixe();
t = new Terme (ADD, t, expressionPrefixe()); break;
case Lexeme.L_Mul: avancer(); t = expressionPrefixe();
t = new Terme (MUL, t, expressionPrefixe()); break;
default: throw new Error ("Erreur de syntaxe");
}
if (lc.nature != Lexeme.L_ParD) throw new Error ("Il manque ')'");
default: throw new Error ("Erreur de syntaxe");
}
avancer();
return t;
} |
Cette fonction ne fait donc aucun retour en arrière. Cette technique
d'analyse syntaxique donné s'étend à toute grammaire LL. Ici on
détermine la règle à appliquer en regardant deux lexèmes à l'avance
dans le flot de lexèmes d'entrée. La grammaire est dite LL(k) si on
peut détermier la règle à appliquer dans l'analyse descendante en
regardant k lexèmes à l'avance. Alors on peut énoncer le résultat
suivant:
Théorème 2
Si G est une grammaire LL(k), il existe un algorithme en
O(n) qui effectue l'analyse syntaxique descendante d'un mot f de
longueur n.
En fait, cet algorithme sert principalement pour k £ 2. On peut
le contruire en prenant la grammaire en paramètre. C'est ce que font
des méta-analyseurs syntaxiques comme javacc. En outre, une
définition formelle des analyseurs LL peut être donnée en considérant
la théorie des automates à pile.
Pour finir, reconsidérons le cas des expressions arithmétiques
infixées. La grammaire suivante n'est pas LL, car il est difficile
de distinguer les applications des règles E ® P et E ® P + E
en regardant k lettres à l'avance.
| E ® P |
|
P ® F |
|
F ® a |
| E ® P + E |
|
P ® F × P |
|
F ® ( E ) |
| E ® P E' |
|
P ® F P' |
|
|
| E' ® e |
|
P' ® e |
|
F ® a |
| E' ® + P E' |
|
P' ® × F P' |
|
F ® ( E ) |
| 2.11.3 |
Analyse ascendante |
|
Les algorithmes d'analyse ascendante sont légèrement plus compliqués
que ceux de l'analyse descendante. Ils s'appliquent à un plus grand
nombre de grammaires. C'est pour cette raison qu'on les utilise
souvent. Ils sont ainsi à la base du système yacc de S. Johnson
qui sert à écrire des compilateurs sous le système Unix.
Rappelons que l'analyse ascendante consiste à retrouver la dérivation
S0 ® u1 ® u2 ... un-1 ® un = f
en commençant par un-1 puis un - 2 et ainsi de
suite jusqu'à remonter à l'axiome S0. On effectue ainsi ce que
l'on appelle des réductions car il s'agit de remplacer un
membre droit d'une règle par le membre gauche correspondant, celui-ci
est en général plus court.
Un exemple de langage qui n'admet pas d'analyse syntaxique
descendante simple, mais sur lequel on peut effectuer une analyse
ascendante est le langage des systèmes de parenthèses. Rappelons sa
grammaire:
| S ® aS bS |
|
S ® aS b |
|
S ® abS |
|
S ® ab |
Partons de f et commençons par tenter de retrouver la
dernière dérivation, celle qui a donné f = un à partir d'un mot
un-1. Nécessairement un-1 contenait un S qui a été
remplacé par ab pour donner f. L'opération inverse consiste donc
à remplacer un ab par S, mais ceci ne peut pas être effectué
n'importe où dans le mot, ainsi si on a
f= ababab
il y a trois remplacements possibles donnant
Sabab abSab ababS
Les deux premiers ne permettent pas de poursuivre l'analyse. En
revanche, à partir du troisième, on retrouve abS et finalement
S. D'une manière générale, on remplace ab par S chaque fois
qu'il est suivi de b ou qu'il est situé en fin de mot. Les autres
règles de grammaires s'inversent aussi pour donner des règles
d'analyse syntaxique. Ainsi:
- Réduire aSb en S s'il est suivi de b ou s'il est situé
en fin de mot.
- Réduire ab en S s'il est suivi de b ou s'il est situé en
fin de mot.
- Réduire abS en S quelle que soit sa position.
- Réduire aSbS en S quelle que soit sa position.
On a un algorithme du même type pour l'analyse des expressions
arithmétiques infixes engendrées par la grammaire:
|
|
| E ® P |
|
P ® F |
|
F ® a |
| E ® E + P |
|
P ® P × F |
|
F ® (E) |
| E ® E - P |
|
|
Pour effectuer une réduction, cet algorithme tient compte de
la première lettre qui suit le facteur que l'on envisage de réduire
(et de ce qui se trouve à gauche de ce facteur). On dit que la
grammaire est LR(1). La théorie complète de ces grammaires
mériterait un plus long développement; elle correspond à la notion de
langages générés par des automates déterministes. Nous nous contentons
de donner ici ce qu'on appelle l'automate LR(1) qui effectue
l'analyse syntaxique de la grammaire, récursive à gauche, des
expressions infixes.
On lit le mot à analyser de gauche à droite et on effectue les
réductions suivantes dès qu'elles sont possibles:
- Réduire a en F quelle que soit sa position.
- Réduire (E) en F quelle que soit sa position.
- Réduire F en T s'il n'est pas précédé de *.
- Réduire T*F en T quelle que soit sa position.
- Réduire T en E s'il n'est pas précédé de + et
s'il n'est pas suivi de *.
- Réduire E + T en E s'il n'est pas suivi de *.
- Réduire E - T en E s'il n'est pas suivi de *.
On peut gérer le mot réduit à l'aide d'une pile. Les opérations de
réduction consistent à supprimer des éléments dans celle-ci, les tests
sur ce qui précède ou ce qui suit se font très simplement en
consultant les premiers symboles de la pile. L'analyse se fait en une
seule passe sur le mot à analyser, donc sans retours en arrière. Comme
pour le cas LL(k), on a le théorème suivant pour les grammaires
LR(k).
Théorème 3
Si G est une grammaire LR(k), il existe un algorithme en
O(n) qui effectue l'analyse syntaxique descendante d'un mot f de
longueur n.
| 2.12 |
Programmes sur les arbres de syntaxe abstraite |
|
L'analyse syntaxique consiste à construire des arbres de syntaxe
abstraite. Dans cette section, nous donnons quelques exemples
d'utilisation de cette structure.
Pour évaluer la valeur d'un terme correspondant à une expression
arithmétique, il faut se donner une valuation des variables,
c'est-à-dire une fonction associant une valeur à chacune des variables
contenues dans ce terme. Le graphe de cette fonction est appelé un
environnement. Le programme pour évaluer une expression correspond au
morphisme suivant sur les arbres de syntaxe abstraite:
static int evaluer (Terme t, Environnement e) {
switch (t.nature) {
case ADD: return evaluer (t.a1, e) + evaluer (t.a2, e);
case SUB: return evaluer (t.a1, e) - evaluer (t.a2, e);
case MUL: return evaluer (t.a1, e) * evaluer (t.a2, e);
case DIV: return evaluer (t.a1, e) / evaluer (t.a2, e);
case CONST: return t.val;
case VAR: return Environnement.assoc (t.nom, e);
default: throw new Error ("Erreur dans evaluation");
}
} |
où la classe Environnement définit la liste d'association
suivante:
class Environnement {
String nom;
int val;
Environnement suivant;
static int assoc (String s, Environnement e) {
if (e == null) throw new Error ("Variable non définie");
if (e.nom.equals(s)) return e.val;
else return assoc (s, e.suivant);
}
} |
Parfois, on dit aussi que la fonction evaluer est définie par
induction structurelle sur la classe des termes.
Un autre programme classique sur les arbres de syntaxe abstraite
consiste à les imprimer. C'est la fonction inverse de
l'analyse syntaxique, puisqu'il s'agit de générer une chaîne de
caractères, dont l'analyse syntaxique produirait le même arbre. Dans
le cas des expressions arithmétiques, plusieurs programmes
d'impression sont possibles. Le plus simple est de produire les
expressions complètement parenthésées. Par exemple, avec l'ASA de la
figure 2.3, on obtiendrait ((x+1)×((3×
y)+2)). L'idéal est plutôt de produire une impression avec le minimum
de parenthèses, comme (x+1)×(3× y +2). Notre
programme sera le symétrique de l'analyseur syntaxique:
static void impExp (Terme t) {
switch (t.nature) {
case ADD: impProd(t.a1); System.out.print ("+"); impExp(t.a2); break;
case SUB: impProd(t.a1); System.out.print ("-"); impExp(t.a2); break;
default: impProd(t); break;
}
}
static void impProd (Terme t) {
switch (t.nature) {
case MUL: impFact(t.a1); System.out.print ("*"); impProd(t.a2); break;
case DIV: impFact(t.a1); System.out.print ("/"); impProd(t.a2); break;
default: impFact(t); break;
}
}
static void impFact (Terme t) {
switch (t.nature) {
case CON: System.out.print (t.valeur); break;
case VAR: System.out.print (t.nom); break;
default: System.out.print ("("); impExp(t); System.out.print (")"); break;
}
} |
Exercice 16
Faire le programme d'impression avec la règle d'association à gauche pour
les opérateurs de même précédence.
| 2.12.3 |
Génération de code |
|
Il s'agit de générer du code machine pour calculer des expressions
arithmétiques sur un processeur simplifié. Notre machine a des
registres Ri dans lesquels s'effectuent les opérations
arithmétiques. Les registres peuvent recevoir une constante n
(entière) ou être chargés à partir d'une mémoire x. Le jeu complet
des instructions de notre processeur est le suivant:
| Ri ¬ n |
|
Ri ¬ Ri + Rj |
|
Ri ¬ Ri × Rj |
| Ri ¬ x |
|
Ri ¬ Ri - Rj |
|
Ri ¬ Ri / Rj |
Ainsi pour évaluer l'expression (x+1)× (3 × (y+2)) (dont
l'arbre de syntaxe abstraite est sur la
figure 2.4), on peut générer par exemple un des
deux codes suivants:
| R0 ¬ x |
|
R0 ¬ x |
| R1 ¬ 1 |
|
R1 ¬ 1 |
| R0 ¬ R0 + R1 |
|
R0 ¬ R0 + R1 |
| R1 ¬ 3 |
|
R1 ¬ y |
| R2 ¬ y |
|
R2 ¬ 2 |
| R3 ¬ 2 |
|
R1 ¬ R1 + R2 |
| R2 ¬ R2 + R3 |
|
R2 ¬ 3 |
| R1 ¬ R1 × R2 |
|
R2 ¬ R2 × R1 |
| R0 ¬ R0 × R1 |
|
R0 ¬ R0 × R2 |
| reg(x) = reg(n) = 1 |
| reg(e Å e')= |
ì
í
î |
| 1 + reg(e) |
si reg(e) = reg(e') |
| max(reg(e), reg(e')) |
sinon |
|
|
|
static int reg (Terme t) {
switch (t.nature) {
case ADD: case SUB: case MUL: case DIV:
int n1 = reg(t.a1), n2 = reg(t.a2);
if (n1 == n2) return 1 + n1;
else return Math.max(n1,n2);
case CONST: case VAR: return 1;
default: throw new Error ("Erreur dans evaluation");
}
}
static int genCode (Terme t, int r0) {
switch (t.nature) {
case ADD: case SUB: case MUL: case DIV:
int n1 = reg(t.a1), n2 = reg(t.a2);
if (n1 >= n2) {
int r1 = genCode(t.a1, r0), r2 = genCode(t.a2, r1);
System.out.println ("R" + r1 + " <- R" + r1 + " + R" + r2);
return r1;
} else {
int r2 = genCode(t.a2, r0), r1 = genCode(t.a1, r2);
System.out.println ("R" + r2 + " <- R" + r2 + " + R" + r1);
return r2;
}
case CONST:
System.out.println ("R" + r0 " <- " + t.val);
return r0;
case VAR:
System.out.println ("R" + r0 " <- " + t.nom);
return r0;
default: throw new Error ("Erreur dans evaluation");
}
} |
A nouveau, la fonction genCode est définie par
induction structurelle sur la classe des termes. On comprend bien sur
cette exemple la nécessité de la phase d'analyse syntaxique, qui a
permis de bien isoler la structure sur laquelle s'effectue la
génération de code, à savoir la structure de syntaxe abstraite. Bien
sûr, il existe des techniques beaucoup plus sophistiquées pour générer
du code. C'est l'objet de tout le domaine de la compilation. Par
exemple, on peut tenir compte du partage, et ne pas recalculer des
expressions déjà calculées; ainsi, dans (x+1)× (3 ×
(x+1)), ce n'est pas la peine de générer deux fois le code de
x+1. Un autre exemple est de tenir compte de la non banalisation des
registres, certaines opérations ne pouvant se faire que dans des
registres pairs. Un troisième exemple consiste à tenir compte de la
durée de vie des variables, en supposant que les déclarations de
variables ont une certaine portée. Tout cela nous entrainerait trop
loin, mais fait partie de la problématique standard de la compilation.
Une autre curiosité a trait aux nombres reg(e) exprimant le nombre
de registres minimaux pour le calcul de e. Ce sont des entités que
l'on peut définir sur tout arbre binaire, même ceux qui ne
correspondent pas à des arbres de syntaxe abstraite. Ces nombres de
Horton-Strahler ont un correspondant en hydrologie et en
botanique. Ils donnent l'épaisseur d'une rivière en fonction de
l'épaisseur de ses affluents, ou d'une branche en fonction de sa
structure de branchement.
type asa =
Feuille of char
| Noeud of char * asa * asa;;
exception Erreur_de_syntaxe of int;;
let f = " (a + a * a ) ";;
let i = ref 0;;
let rec expression () =
let a = terme () in
if f.[!i] = '+' then begin
incr i;
Noeud ('+', a, expression ()) end
else a
and terme () =
let a = facteur () in
if f.[!i] = '*' then begin
incr i;
Noeud ('*', a, terme ()) end
else a
and facteur () =
if f.[!i] = '(' then begin
incr i;
let a = expression () in
if f.[!i] = ')' then begin
incr i;
a end
else raise (Erreur_de_syntaxe !i) end
else
if f.[!i] = 'a'
then begin
incr i;
Feuille 'a' end
else raise (Erreur_de_syntaxe !i);; |
(* Prédicat définissant les non-terminaux *)
let est_auxiliaire y = ... ;;
(* règle.(s).(i) est la ième règle
dont le membre gauche est s *)
let règle =
[| [| s00; s01; ... |];
[| s10; s11; ... |];
[| si0; si1; ... |];
... |];;
(* nbrègle.(s) est le nombre de règles
dont le membre gauche est s *)
let nbrègle = [| s0; ...; sn |];;
(* Fonction auxiliaire sur les chaînes
de caractères: remplacer s pos char
renvoit une copie de la chaîne s
avec char en position pos *)
let remplacer s pos char =
let s1 = String.make (String.length s) ' ' in
String.blit s 0 s1 0 (String.length s);
s1.[pos] <- char;
s1;;
let analyse_descendante f u =
let b = ref false in
let pos = ref 0 in
while f.[!pos] = u.[!pos] do incr pos done;
if f[!pos] = '$' && u.[!pos] = '#'
then
true
else
let y = u.[!pos] in
if est_auxiliaire y
then begin
let i = ref 0 in
let ynum = int_of_char y - int_of_char 'A' in
while not !b && !i <= nbrègle.(ynum) do
b := analyse_récursive
(remplacer (u, !pos, règle.(ynum).(!i)), f);
else incr i
done;
!b end
else false;; |
(* Analyse LL(1), voir page ?? *)
let rec arbre_synt_pref () =
if f.[!pos] = 'a'
then begin
incr pos;
Feuille 'a' end
else
if f.[!pos] = '('
&& f.[!pos + 1] = '+'
|| f.[!pos + 1] = '*'
then begin
let x = f.[!pos + 1] in
pos := !pos + 2;
let a = arbre_synt_pref () in
let b = arbre_synt_pref () in
if f.[!pos] = ')'
then Noeud (x, a, b)
else erreur (!pos) end
else erreur(!pos);; |
(* Évaluation, voir page ?? *)
type expression =
| Constante of int
| Opération of char * expression * expression;;
let rec évaluer = function
| Constante i -> i
| Opération ('+', e1, e2) -> évaluer e1 + évaluer e2
| Opération ('*', e1, e2) -> évaluer e1 * évaluer e2;; |