


Chapitre 1 : HEVEA
1.1 Introduction
HEVEA est un programme de traduction du langage LATEX vers le langage HTML.
La diffusion de documents sur internet se fait essentiellement grâce au `web' et au langage HTML. Celui-ci permet en effet de se déplacer dans le document de manière intuitive et facile grâce aux liens hypertexte, de sélectionner du texte pour le copier ailleurs tout en aillant un rendu visuel très correct.
Cependant, une très grande proportion des publications scientifiques est préparée à l'aide de LATEX, qui est un logiciel de formatage de texte très répandu et largement utilisé dans la communauté scientifique, ayant un rendu final professionnel et une grande facilité d'utilisation. Pour pouvoir mettre à disposition sur internet ces documents, on a alors plusieurs solutions : soit on rend le source LATEX disponible, ce qui oblige l'utilisateur à le recompiler, soit on le compile et on partage un des formats de sortie : dvi ou postscript. Cette dernière solution n'est valable que si celui qui veux consulter le document peut l'imprimer, car la visualisation de tels documents n'est pas très pratique. La traduction de LATEX vers HTML se révèle alors utile et même nécessaire pour allier les avantages de ces deux systèmes.
Plusieurs logiciels existent déjà pour effectuer ce travail. Parmi eux on trouve latex2html ou tth. HEVEA a été écrit par Luc Maranget, en utilisant le langage Objective Caml développé à l'INRIA et est très rapide par rapport à ses concurrents. Il prend en entrée un fichier correspondant au langage LATEX2e. Le fichier HTML produit répond aux spécifications de la norme HTML 3.2 [10]. Un manuel de référence d'HEVEA peut être trouvé en [9], ainsi qu'un article décrivant son fonctionnement dans le mode HTML en [8].
Les différents environnements de LATEX sont rendus par la pose des tags correspondants en HTML. Les deux langages étant structurellement assez proche, l'opération est facilitée. Il y a évidemment quelques adaptations. Par exemple, les formules mathématiques sont traduites en utilisant la fonte SYMBOL d'HTML. Cette fonte n'est pas standard, mais est présente dans tous les visualiseurs courants. Pour les équations, les tableaux d'HTML sont utilisés pour aligner correctement les différents éléments de la formule.
Un autre avantage d'HEVEA est l'utilisation des macros : HEVEA permet de définir et de redéfinir les macros LATEX, ce qui donne une grande souplesse d'utilisation et d'adaptation aux documents traduits.
En fait, on se rend vite compte qu'il est beaucoup plus pratique de taper un texte en LATEX et de le traduire ensuite en HTML, que de créer directement un fichier HTML. Cette méthode a en plus l'avantage énorme de laisser le choix sur le format du fichier final : postscript ou HTML, à partir d'un même fichier source. Une extension d'HEVEA consiste alors à traduire LATEX vers d'autres formats de fichiers. C'est le sujet de mon stage : compléter et améliorer HEVEA. Cela se traduit par le rajout de plusieurs modules permettant de gérer de nouveaux formats et nécessite une réorganisation de certains modules existant déjà.
J'ai traité les formats suivants :
-
texte:
- Formatage en texte au format ASCII, avec extension pour les caractères spéciaux. La difficulté de ce format vient du fait qu'il n'est plus interprété par la suite : le document doit être formaté entièrement, y compris les tableaux et les formules mathématiques.
- info:
- Ce format de fichier permet de réaliser des manuels consultables sous emacs ou dans un `x-term' à l'aide du programme
info . Il met en place un système de références et de menus, ce qui permet de structurer le document en le rendant plus lisible. Le formatage de texte est le même que celui en mode texte.
- mathml:
- C'est la future extension de HTML, allant avec HTML 4.0. Cela permettra de diffuser des formules mathématiques sur le web, avec un langage de description respectant la structure logique des formules mathématiques.
Je vais dans un premier temps décrire le fonctionnement général d'HEVEA, et la structure de reconnaissance de LATEX sur laquelle je me suis appuyé pour programmer. Ensuite, j'expliquerai la démarche que j'ai suivi pour concevoir les modules d'extension pour le texte et l'info, et leur mode de fonctionnement. Ceux-ci devant en effet avoir exactement la même interface que le module générant de l'HTML. Puis nous verrons Le module gérant le mathml, qui s'insère dans le module HTML.
1.2 Organisation
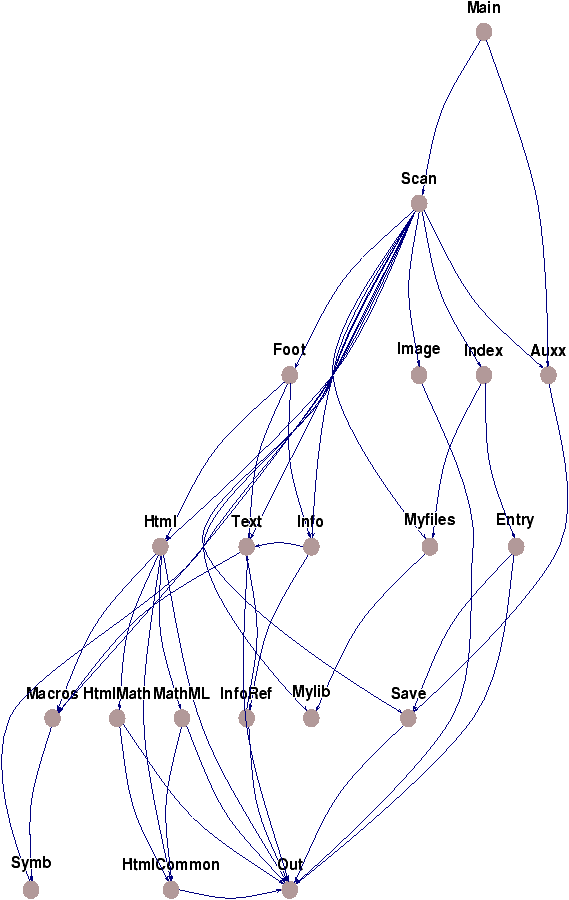
Figure 1.1 :
Les dépendances entre modules d'H
EV
EA
HEVEA est programmé en Objective Caml, et je vais maintenant en décrire le fonctionnement général. Les deux parties principales sont d'une part la lecture du fichier LATEX, et de l'autre la production du fichier de sortie, quel que soit son format.
Il est donc organisé autour d'un module qui analyse le fichier d'entrée, et appelle directement les fonctions du gestionnaire de sortie. Celles-ci sont suffisemment génériques pour avoir le plus souvent une interface indépendante du format de sortie et correspondent donc en général à des concepts LATEX.
Les gestionnaires de sorties sont des modules qui vont être passés en argument au foncteur1 qui va créer le module Scan.
Les gestionnaires de sorties se trouvent respectivement dans les modules Html, Text et Info. Leur interface est évidemment identique.
HEVEA utilise de nombreux modules, pour clarifier le code et séparer les opérations. Les dépendances entre les modules sont données Figure 1.1.
Voici une description des différents modules, classés par leur fonction dans le programme.
-
Tout d'abord, deux modules généraux:
-
Latexmain
- Module principal d'HEVEA. Il procède au chargement des fichiers de définition des macros, et appelle
Scan en lui donnant en argument le bon module de destination.
- Scan
- Analyseur principal. Il gère la mise en place des tableaux et réalise les appels au module de destination. L'analyseur reconnait un petit nombre de commandes, et procède essentiellement par reconnaissance des macros.
- Les modules de sorties sont les suivants :
-
Html
- Produit un fichier HTML conforme à la norme 3.2. Il utilise les modules :
-
HtmlCommon
- Fonctions générales utilisées par les autres modules.
- HtmlMaths
- Mathématiques en mode HTML 3.2, en utilisant les tableaux.
- MathML
- Mathématiques en MathML.
- Text
- Produit une sortie en texte formaté.
- Info
- Donne un fichier info. Ce module appelle essentiellement le module
Text pour tout le formatage, et le module InfoRef pour ce qui est spécifique au format info.
- InfoRef
- Lexer supplémentaire pour le format info. Permet de faire une seconde passe sur le fichier de sortie pour mettre à jour les liens et découper éventuellement le fichier.
- Quelques modules sont très utilisés :
-
Out
- Gestion de toutes les sorties. Ce module permet d'abstraire la sortie, et de traiter avec les mêmes fonctions une sortie sur disque, dans un tampon texte ou dans le vide.
- Macros
- Gestion de l'environnement des commandes LATEX.
- Save
- Analyseur lexical qui lit les arguments des commandes.
- HEVEA utilise d'autres analyseurs lexicaux :
-
Auxx
- Lecture des fichiers auxiliaires .aux produits par LATEX. Les informations lues permettent à Scan d'introduire dans sa sortie les étiquettes des références croisées et des citations bibliographiques.
- Entry
- Lecture du fichier d'index .idx. Cette lecture est optionnelle, elle s'impose lorsque l'utilisateur modifie ce fichier après sa production par LATEX.
- La gestion des entrées et des sorties est faite par
Out et deux modules :
-
Mylib
- Localisation du répertoire de la librairie d'HEVEA et gestion du chemin de recherche des fichiers.
- Myfiles
- Localisation et ouverture des fichiers.
- Enfin, on trouve plusieurs modules spécifiques à certaines tâches :
-
Index
- Production de l'index.
- Foot
- Gestion des notes de bas de page.
- Symb
- Définition des symboles mathématiques.
- Image
- Production d'un fichier LATEX qui regroupe les sous-parties du source traduit à transformer en images. Le document final contient ensuite des liens vers les images en lieu du source transformé. Cette procédure est toujours demandée explicitement par l'utilisateur et ne fonctionne qu'en mode HTML.
1.3 Lecture de LATEX
Le module Scan est le corps de l'analyseur d'HEVEA. Il est compilé avec l'aide du générateur de lexer ocamllex fourni dans la distribution d'Objective Caml. Il fonctionne par reconnaissance des lexèmes définis dans le fichier latexscan.mll. La quasi-totalité des commandes sont définies comme étant des macros. Il faut alors commencer par initialiser le programme en définissant toutes les macro-commandes, puis l'analyseur détecte les unités syntaxiques et traite uniquement les cas simples et les macros. Ce système donne une grande souplesse d'utilisation pour la redéfinition des commandes, éventuellement par l'utilisateur.
Scan a été crée par application d'un foncteur avec pour argument le module de sortie. Le nom générique de ce module de sortie à l'intérieur de Scan est Dest.
1.3.1 Unités syntaxiques
Unités élémentaires
Il faut reconnaître les unités élémentaires comme les commentaires, le passage en mode mathématiques. Le traitement des caractères retour chariot `\n' est particulier, puisqu'il faut rassembler tous les retours chariots consécutifs en un seul, en changeant de paragraphe s'il y en a plus d'un et en insérant juste un séparateur s'il y en a un seul. Par exemple, le traitement des retouts chariots est fait ainsi :
rule main = parse
(* Paragraphs *)
| '\n' +
{let nlnum = String.length (lexeme lexbuf) in
(...) begin
if nlnum >= 2 then
top_par (par_val !in_table)
else
Dest.put_separator () ;
main lexbuf
end}
Si l'on a plus de deux caractères `\n', on appelle top_par qui va insérer un saut de paragraphe. Sinon, on met juste un séparateur à l'aide de Dest.put_separator.
On reconnait aussi le passage en indices et exposant à ce niveau, ainsi que les groupes : `{' et `}'. Cela correspond à l'ouverture et la fermeture de blocs dans le gestionnaire de sortie.
Tous les autres caractères, qui ne correspondent pas à une commande, sont retransmis directement au module de sortie Dest, à l'exception des caractères alphabétiques en mode mathématiques, qui doivent être rendus différemment. Ainsi la ligne LATEX:
$identificateur$
devant être rendue ainsi : identificateur, sera traduite en HTML par :
<I>identificateur</I>
alors qu'en texte, on ne peut faire une telle distinction, et on affichera simplement: identificateur. Cette différence de comportement est gérée par un appel à la fonction Dest.put_in_math où Dest correspondra suivant les cas à Html, Text ou Info, et qui sera différente dans chacun des modules.
On peut alors bien différencier le comportement de chaque sortie.
Commandes LATEX
Les commandes sont reconnues à l'aide de l'expression régulière suivante :
'\\' (('@' ? ['A'-'Z' 'a'-'z']+ '*'?) | [^ 'A'-'Z' 'a'-'z'])
C'est à dire qu'une commande correspond à une suite de caractères commençant par `\', suivie soit d'un seul caractère non alphabétique, soit de caractères alphabétiques, éventuellement précédés d'un `@' pour les commandes internes d'HEVEA et/ou suivis d'un `*' pour les commandes étoilées de LATEX.
Toutes les commandes sont donc définies comme des macros à l'aide de la fonction def_code à l'intérieur du code Caml, ou comme des commandes LATEX usuelles. D'ailleurs, une majorité des commandes LATEX sont définies comme des macros, en LATEX dans le fichier hevea.hva, ou les fichiers de style article.hva. Ces fichiers sont l'équivalent des fichiers .sty de LATEX.
La gestion des macros se fait dans le module Latexmacros. En fait, on enregistre dans une table de hachage le nom de la macro associé à une paire représentant les arguments et l'action de la commande :
type action =
| Subst of string
| CamlCode of (Lexing.lexbuf -> unit)
type pat = string list * string list
let cmdtable =
(Hashtbl.create 97 : (string, (pat * action)) Hashtbl.t);;
let def_macro_pat name pat action =
try
let _ = Hashtbl.find cmdtable name in () ;
warning ("ignoring definition of "^name) ;
raise Failed
with
Not_found ->
Hashtbl.add cmdtable name (pat,action)
let def_code name f = def_macro name 0 (CamlCode f)
Les arguments des commandes LATEX sont de deux types, selon [6] : soit on a n arguments obligatoires, soit on a un argument optionnel et (n-1) arguments obligatoires.
Les fonctions sont appelées différemment selon les cas :
command{arg1}{arg2}...{argn}
ou
command[arg1]{arg2}...{argn}
Le type pat permet de gérer ces deux types d'arguments : c'est une paire de deux listes de chaines représentant les valeurs par défaut des arguments. Evidemment, ces valeurs par défaut ne serviront que pour les arguments optionnels. Cela permet juste de faire un compte des arguments et de traiter les deux types de la même manière.
Il suffit ensuite de définir les commandes. Par exemple, pour la commande \item :
def_code "\\over"
(fun lexbuf ->
Dest.over !display lexbuf;
skip_blanks lexbuf)
;;
On réalise directement l'appel au module de destination, avec comme arguments un booléen !display qui indique si on est en mode matématiques display, et le flot de lexèmes lexbuf. Cette commande sera sauvegardée dans la table de commandes comme étant du type CamlCode.
Le cas d'une macro utilisateur est légèrement différent. En effet, il faut substituer le code LATEX à la place de la commande, tout en remplaçant les paramètres #1, #2, ..., #9 par les arguments correspondant.
Ceci est réalisé par un appel à la fonction scan_this qui utilise une fonctionnalité de l'analyseur lexical de Caml qui permet d'analyser une chaine de caractères avec la fonction Lexing.from_string. On analyse le flot de léxèmes ainsi obtenu par l'analyseur principal d'HEVEA:
let scan_this lexfun s =
let lexer = Lexing.from_string s in
lexfun lexer in
Le remplacement des arguments se fait lors de l'analyse principale. Les arguments sont sauvegardés avant l'appel de la commande dans un tableau dont on a la référence : stack. Ce tableau est sauvegardé récursivement à chaque appel imbriqué de fonction dans une pile. Lors de l'évaluation de l'argument, on va chercher celui-ci dans le tableau, puis on utilise scan_this pour l'évaluer en prenant soin de dépiler le tableau des arguments et de le rempiler après pour avoir le bon environnement d'arguments.
1.3.2 Environnements
Les environnements LATEX correspondent à des entités de texte bien définies sur lesquelles on va appliquer un certain style, ou une mise en page différente, où certains caractères peuvent changer de signification, comme & dans les tableaux. Dans HEVEA, on trouve le concept de bloc dans le module de destination. Chaque environnement va correspondre à un bloc, avec des arguments spécifiques le décrivant. Le module de destination analysera ensuite les arguments et réalisera l'environnement.
Les blocs doivent évidemment pouvoir s'imbriquer et sont gérés par l'interface suivante :
val open_block : string -> string -> unit
val close_block : string -> unit
val force_block : string -> string -> unit
val insert_block : string -> string -> unit
val erase_block : string -> unit
Ces fonctions permettent d'ouvrir et de fermer les blocs. force_block force la fermeture d'un bloc et erase_block annule le bloc en cours. insert_block permet d'insérer après coup un changement de style dans le bloc courant.
1.3.3 Mode mathématiques
LATEX possède un environnement mathématique très puissant qui permet d'écrire des équations et des formules mathématiques facilement.
Cependant, les formats de sortie HTML, texte et info n'ont aucune gestion des symboles et des formules mathématiques. Il faut donc adapter le modèle LATEX à chacun des formats. Le mode MathML n'a pas ces difficultés, mais il doit être compatible avec les autres. A la lecture des formats LATEX [6] et [4], puis mathML [5], j'ai pu extraire une interface commune à tous les modules, mettant en avant les concepts d'alignement des formules.
On trouve essentiellement deux problèmes : traduire les symboles et les caractères mathématiques, et gérer le positionnement et l'alignement de ces symboles. Les solutions adoptées en HTML sont décrites dans [8]
Les symboles sont traduits dans le module Symb et dans les fichiers de macros symb*.hva, soit en utilisant la fonte SYMBOL pour l'HTML, soit en donnant un caractère approché.
Les alignements sont rendus en utilisant les tableaux. on introduit des displays qui vont englober les formules et permettre le positionnement à l'intérieur de cases d'un tableau.
Les formules doivent avoir deux modes de rendu, selon que l'on est en cours de texte, ou en mode display, ouvert en LATEXpar $$.
L'interface est la suivante. On entre et on sort du mode mathématiques par:
val open_maths : bool -> unit
val close_maths : bool -> unit
L'argument est un booléen déterminant si on est en mode display.
Ensuite, si on est pas en mode display, la formule va nécessiter moins de traitements, car le postionnement est sur une seule ligne. Dans le cas contraire, il faut ouvrir un ``display''. Ceci désigne l'unité de groupement horizontal des formules. On a les fonctions :
val open_display : string -> unit
val close_display : unit -> unit
val item_display : unit -> unit
val force_item_display : unit -> unit
val erase_display : unit -> unit
On ouvrira et fermera des displays chaque fois que cela sera nécessaire. On peut les imbriquer et ils vont correspondre, par exemple, à tous les groupements entre deux délimiteurs ou aux lignes d'indices ou d'exposants.
On peut annuler un display par erase_display. Les deux fonctions restantes vont permettre un groupement des expression un peu plus fin. En effet, après chaque symbole ou chaque entité, on va appeler l'une de ces deux fonctions pour introduire une séparation à ce niveau dans la formule. On peut considérer, comme dans le modèle HTML ou texte, que le display correspond à un tableau horizontal et que item_display passe à la case suivante du tableau.
Ensuite, il faut prendre en compte quelques positionnements particuliers. Ce sont les indices, les exposants, les fractions et les délimiteurs.
Les indices et exposants ont un traitement simultané. Ils sont de trois types, selon que l'indice ou l'exposant est après la variable concernée, en distinguant le cas de l'intégrale et le cas standard : ò01 ou x2. On peut aussi les trouver au même niveau :
On a donc trois fonctions pour produire les indices et les exposants :
val standard_sup_sub :
(string -> unit) -> (unit -> unit) -> string -> string ->
bool -> unit
val limit_sup_sub :
(string -> unit) -> (unit -> unit) -> string -> string ->
bool -> unit
val int_sup_sub :
bool -> int -> (string -> unit) -> (unit -> unit) -> string ->
string -> bool -> unit
Ces trois fonctions prennent comme argument une fonction d'analyse, une fonction qui écrira la partie principale de l'expression, puis deux chaînes représentant l'exposant et l'indice. Enfin un booléen correspond au mode display.
int_sup_sub prend deux arguments supplémentaires au début qui seront un booléen qui sera vrai si la partie de base de l'expression est non vide, et un entier donnant la hauteur de l'expression.
Les fractions sont créees par la fonction over:
val over : bool -> Lexing.lexbuf -> unit
Le booléen donné en argument correspond encore au mode display. On appelle cette fonction après avoir analysé le numérateur, comme dans la commande \over de LATEX. Le module de sortie doit donc revenir en arrière pour déterminer ce numérateur et insérer l'environnement de la fraction. Il faut en fait remonter jusqu'au dernier appel à open_display, c'est à dire au dernier bloc logique.
Enfin, les délimiteurs sont posés par les deux commandes :
val left : string -> unit
val right : string -> int
Chaque fonction prend en argument le délimiteur à afficher. Ils doivent être bien parenthésés, même si les délimiteurs droit et gauche ne sont pas identiques.
1.3.4 Tableaux
Les tableaux sont définis en LATEX par l'environnement tabular. Les données sont ensuite organisées ligne par ligne. Pour faire un analyseur en une passe, il faut envoyer les données dans l'ordre où elles arrivent au module de destination. Il a fallu déterminer une interface générique entre les différents modèles. J'ai retenu un concept à mi-chemin entre LATEX et HTML, ce qui a simplifié l'implémentation par rapport à ce qui existait déjà en HTML tout en donnant la possibilité d'implémenter le mode texte.
Par exemple, le tableau simple suivant:
est obtenu en LATEX par la séquence d'instructions :
\begin{tabular}{|p{1cm}|r@{.}l|}
\hline
\multicolumn{3}{|c|}{Nombres}\\ \hline
$\pi$ & 3 & 1415927\\
e & 2 & 718\\ \hline
\end{tabular}
En HTML, HEVEA traduit ce tableau ainsi :
<TABLE BORDER=1 CELLSPACING=0 CELLPADDING=1>
<TR><TD ALIGN=center NOWRAP COLSPAN=5>Nombres</TD>
</TR>
<TR><TD VALIGN=top ALIGN=left><FONT FACE=symbol>p</FONT></TD>
<TD ALIGN=right NOWRAP>3</TD>
<TD VALIGN=top ALIGN=center NOWRAP>.</TD>
<TD ALIGN=left NOWRAP>1415927</TD>
</TR>
<TR><TD VALIGN=top ALIGN=left>e</TD>
<TD ALIGN=right NOWRAP>2</TD>
<TD VALIGN=top ALIGN=center NOWRAP>.</TD>
<TD ALIGN=left NOWRAP>718</TD>
</TR></TABLE>
Alors qu'en texte, il faut écrire directement le tableau formaté :
---------------
| Nombres |
---------------
|pi |3.1415927|
|e |2.718 |
---------------
On remarque que les données sont organisées dans le même ordre dans les trois formats.
On va commencer par lire les informations de formatage |p{1cm}|r@{.}l| dans le module Tabular. Celles-ci vont être utilisées ensuite pour décrire chaque ligne du tableau et ouvrir les colonnes et les cellules au bon endroit, ainsi qu'insérer les bordures et les colonnes @. Cela est réalisé au niveau de l'analyseur principal, qui dispose de l'interface suivante avec le module de destination :
val open_table : bool -> string -> unit
val new_row : unit -> unit
val open_cell : Tabular.format -> int -> int -> unit
val erase_cell : unit -> unit
val close_cell : string -> unit
val do_close_cell : unit -> unit
val open_cell_group : unit -> unit
val close_cell_group : unit -> unit
val erase_cell_group : unit -> unit
val close_row : unit -> unit
val erase_row : unit -> unit
val close_table : unit -> unit
val make_border : string -> unit
val make_inside : string -> bool -> unit
val make_hline : int -> bool -> unit
Ces fonctions sont assez génériques. A l'entrée dans un tableau, on commence par un appel à Dest.open_table avec comme arguments un booléen représentant la présence d'une bordure et une chaine d'arguments spécifiques à HTML. En effet, En HTML, il suffit qu'il y ait une indication de bordure `|' dans le format pour qu'on affiche des bordures partout.
On ouvre ensuite une ligne par open_row. Ceci reviend en HTML à poser le tag <TR>, et en texte à initialiser quelques variables.
Puis on arrive aux cellules. On les ouvre par open_cell, en donnant le format de la cellule en argument, ainsi que deux entiers représentant la portée de la cellule (nombre de colonnes sur lesquelles elle s'étend) et le nombre de colonnes @ recouvertes par cette cellule. Ce dernier argument sert uniquement pour les multicolonnes, pour calculer la portée exacte qui n'est pas gérée de la même manière en texte et en HTML.
L'analyseur principal remplit alors la cellule. Si tout s'est bien passé, on va arriver soit à &, soit à \\. Il faut alors fermer la cellule par un appel à close_cell, avec en argument le texte par défaut si la cellule est vide. On peut alors fermer éventuellement la colonne, avant d'ouvrir la suivante. On ouvre alors la cellule suivante. On a donc une cellule ouverte en permanence.
En procédant de cette manière, il arrive des cas où on a ouvert une cellule en trop, par exemple avant la fin du tableau. Il faut pouvoir annuler cette ouverture. Ceci est réalisé par la fonction erase_cell, qui efface la cellule en cours et son contenu. De même, la fonction erase_row efface la ligne courante. Cette fonction ne doit être appelée que si aucune cellule n'est dans cette ligne. La cellule qui avait été ouverte ayant par exemple été fermée avec erase_cell.
Trois fonctions englobent les fonctions d'ouverture et de fermeture des cellules : open_cell_group, close_cell_group et erase_cell_group. Elle permettent d'ouvrir un groupe autour d'une cellule en mode HTML, ce qui protège les données de la cellule avant de les recopier dans le tampon représentant la ligne.
Il reste trois fonctions particulières. Les deux premières permettent de gérer les bordures. make_border place la bordure en argument à la fin de la cellule en cours. En général, cet argument sera ``|''. De même, make_inside place une bordure après la cellule en cours, cette bordure correspondant à une colonne @ de LATEX. Le premier argument est le texte à mettre dans cette bordure, et le deuxième est un booléen qui est vrai si on est dans une multicolonne. En effet, on ne gère pas les colonnes @ en mode HTML dans une multicolonne.
Enfin, make_hline permet de faire une ligne horizontale sur toute la longueur du tableau. Cela effacera la ligne en cours, qui doit normalement être vide.
1.4 HTML
Je ne détaillerai pas ici le fonctionnement de la production d'HTML. Il est expliqué dans [8], et je n'ai fait que quelques modifications de manière à le rendre compatible avec les autres modules de sortie, sans changer le comportement du module.
En HTML 3.2, les tableaux sont formatés par le visualiseur. Il suffit de poser les balises correspondants aux environnements, à l'ouverture et la fermeture des colonnes et des cellules. Ces informations sont contenues dans l'interface avec Scan.
Par contre, les mathématiques ne sont pas gérées par l'HTML. Pour écrire des équations en mode display, un système de tableau a été mis au point. Chaque display correspond en fait à une table HTML divisée en cases pour séparer les éléments. Les éléments verticaux : indices, exposants et fractions, donnent lieu à une création d'un autre tableau, organisé verticalement.
Pour simplifier le code HTML produit et obtenir un meilleur espacement des formules, il faut limiter le nombre de tableaux effectivement crées. En effet, il est inutile d'inclure un tableau dans une case si ce dernier n'a qu'une seule case. De même, les tableaux vides ne seront pas mis.
Au niveau du formatage, les blocs sont implémentés de manière à suivre le formatage des environnements LATEX décrit au paragraphe 1.3.2.
A la gestion des blocs se rajoute une notion de modes qui va permettre de décrire les différents styles utilisés dans le document.
On distingue les modes actifs, qui ont été réalisés dans le mode en cours, et les modes en attente, qui n'ont pas encore été ouverts. A la fermeture d'un bloc, on rajoute au début du bloc tous les modes en attente, qui seront donc valables pour tout le bloc. Puis on ferme tous les modes a la fin du bloc.
On distingue dans HEVEA trois types de style:color pour les changements de couleur, size pour la taille et style pour tous les autres styles.
- 1
- Module d'ordre supérieur, voir [7], section 3.3, The Module System, Functors
